
7 key security features available in SQL Azure
This article is a quick walk-through of some of the key security features which are available in SQL Azure.
The schemaless architecture of MongoDB gives it the flexibility to store huge amounts of data. MongoDB also provides powerful aggregation features to process data for real-time analytics, for many use cases in healthcare, finance, advertising, manufacturing, and the list goes on. Recently, with the rapid developments in generative AI and ChatGPT, several attempts are being made to improve the accuracy and efficiency of the LLM (Large Language Model). One such architecture is the Retrieval Augmented Generation (RAG) architecture, which provides the ground truth and facts to supplement the LLM with its own interpretation of responses.
To achieve this augmentation, MongoDB uses the Vector Search, a powerful capability, that simplifies the application stack and eliminates the need for separate systems for storing and retrieving vectors and the operational data.
Vectors are numerical representations of a text data. Vector is usually represented as v, and consists of an array of numbers (floats or integers).
v = ([1,2,3,4......])
For example, the word ‘artificial intelligence’ can be represented as,
v_ai = ([0.988, 0.3444, -0.45....])
In an n-dimensional space, a vector is represented as a point or coordinate representing the n-dimensions. For example, in a 2-dimensional space, a vector can be characterized by its direction and magnitude.
The most important reason for using vectors is that any type of data, be it text, or image, videos, audios, can be represented numerically in the form of vectors. This enables AI algorithms to process data more efficiently and accurately. For example, for feature extraction, which is one of the most important steps of algorithm training and pattern identification, vectors are used to represent the features extracted from the data.
Vectors are also useful in clustering and classification to group data points based on vector-based distance.
All in all, vectors are a crucial part of building AI systems, as they provide a flexible way to represent data, analyze and manipulate data obtained from multiple sources.
Embedding is the representation of higher dimensional data in lower dimensions. Embedding captures the most essential features of data required for the business problem at hand. Embedding algorithms use vectors to find similar objects, like similar images, similar words, and so on.
In technical terms, when data is fed to a deep neural network, known as the ‘encoder’, the resultant vectors that are generated are called the embeddings. These vectors can be used for similarity search by the deep learning model. The vector representations include the relationships between the different words in the input data. For example, in a sentence such as “Can artificial intelligence replace the human brain”, the embeddings of human will generate the context of the word human, and its relationship with the other words like intelligence, brain and artificial.
These embeddings are created in the hidden layer of a deep neural network. The neural network is first given similar examples for training, and as the embedding hidden layer learns, it starts to generate the output on its own. As the model is fine-tuned, it can produce better results based on the feedback.
For simplicity, let us consider only two dimensions of the vector and plot them graphically. The vectors that are similar (relationship) are plotted together.

In a real-world problem, we would have n-dimensions, where n would be a huge number. The vector representation shows that semantically similar, i.e. words with similar meaning or contextually similar words are clustered together, or are numerically closely placed.
For the same set of words, there might be different ways of clustering. This depends on how the encoder embeds the input data and how the distance between the vectors is calculated.
An example for illustration of the same is given below:
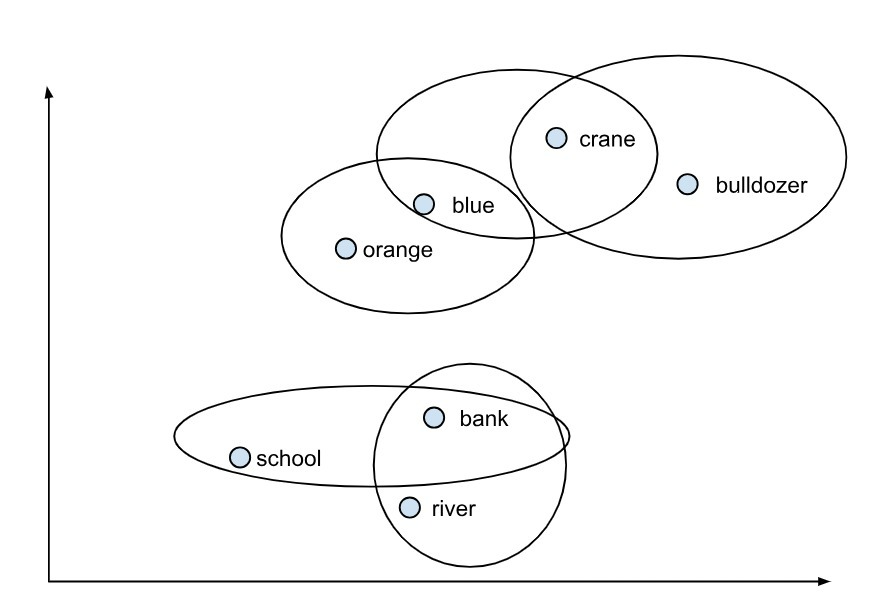
So, if there is a sentence as ‘A crane is near the bank’ could be ambiguous, as the word crane could mean the bird crane as well as the construction vehicle crane. Similarly a bank could be a river bank or the bank building. However, if the word river is included in the sentence, “A crane is near the river bank”, the model can easily identify the context based on the above mapping.
The method in which the model measures the distance between words to find similar words is called vector search. Vector search is currently the most effective and popular method for information retrieval. Vector search uses the approximate nearest neighbor algorithms, like the K-nearest neighbor algorithm to find groups of similar words.

The grouping of vectors based on similarity is done using the K-nearest neighbor algorithm, where K is the number of neighbors being searched for. The K-NN algorithm uses the similarity functions, like euclidean distance between the ends of the vectors, cosine angle between the vectors, or dot product between the vectors. Dot (scalar) product method can find the magnitude (distance) and the direction (angle) of the vectors. MongoDB Atlas Vector search supports all the above methods to find similarity.
For dense data, like that of image classification, euclidean distance is a good choice. For text data, like summarization, where it is important to know the keywords, the cosine method does exceptionally well. When both the orientation and data density are important, dot product is the most efficient choice.
To speed up the retrieval process, MongoDB Atlas vector search uses the approximate nearest neighbor algorithm, which is a less-accurate but higher-speed algorithm compared to the k-nn algorithm. The trade-off with accuracy is almost negligible, however there are significant improvements in the speed.
Atlas vector search works for dimensions as high as 2048, making it a powerful companion to LLMs and embedding.
The problems with LLM is that sometimes it might have old data (not updated after the training is complete) and the model itself might not have access to private data (like company-specific data) to be able to give accurate results.
MongoDB’s vector search stores the vectors alongside the operational data, thus ensuring that all your data is in one place, and easily accessible.
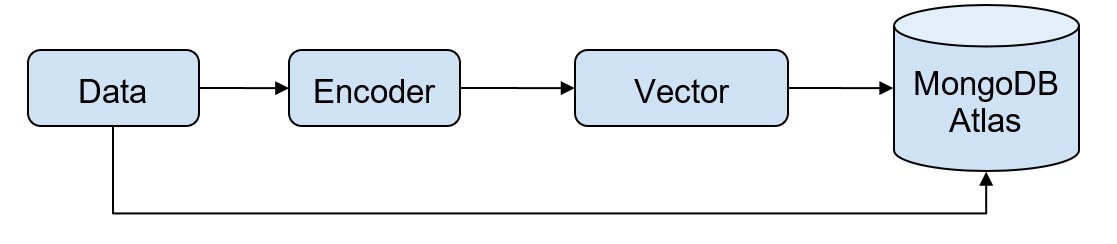
While writing, you can write the data and the vector embeddings as the content into the MongoDB database. While reading, you can encode the query and submit it in the aggregation pipeline $search stage along with the target vector.
All this can be done in just a few steps!
You can write your vector data along with the other content that you are pushing into the document.
{
.....many fields...
content: "text or other unstructured data",
content_embeddings: [0.28, -0.45, 0.53, 0.89, -0.23......]
}
For the search mechanism to understand about these embeddings, provide the index definition in the definition builder as:
"content_embedding": {
{
"type": "knnVector",
"dimensions": <the dimension="" integer="" required="">,
"similarity": "<euclidean>" //one of these
}
}
You can search for the data against the target vector using the MongoDB $search operator by giving the target vector, the path of the embeddings, and the nearest neighbor value (k). You can learn more about this from the MongoDB introductory video on vector search.
MongoDB is a flexible schemaless database that accepts various types of unstructured data, provides powerful capabilities, including the vector search capability, which has enhanced the accuracy of output of large language models. MongoDB vector search augments the existing capability of LLM to provide the facts or truths about the output data, which reduces the hallucination or misleading response. This is achieved through the retrieval architecture.
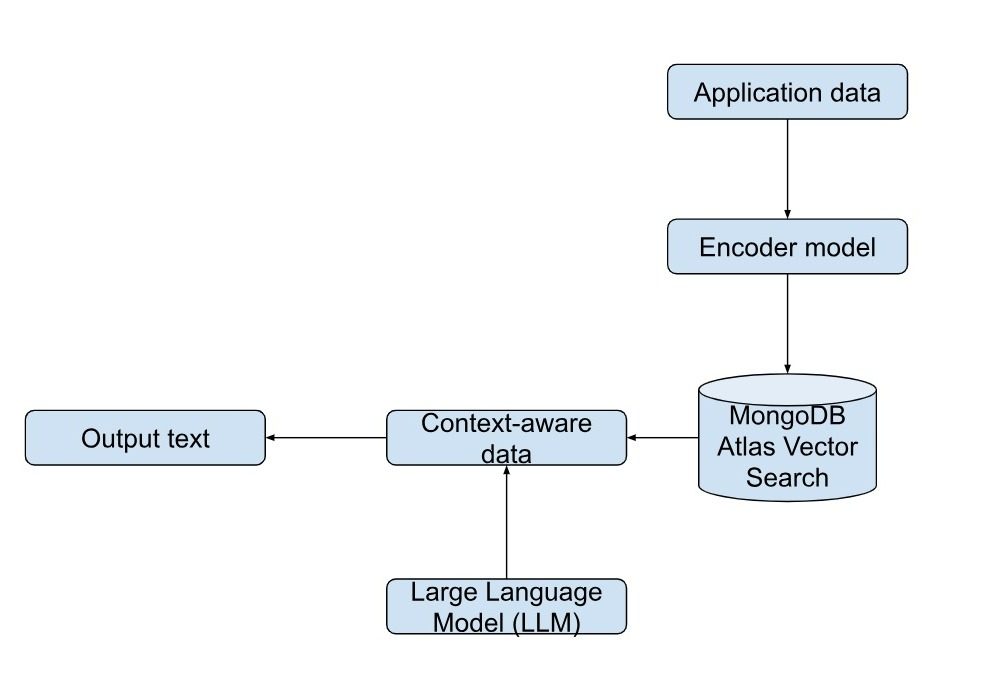
MongoDB Atlas vector search is not only unique because it provides operational data and the vector data into the same platform for semantic search, it is also special because MongoDB Atlas being the fully loaded unified data platform manages everything for its users, from synchronization of data, scaling, security, data privacy and much more. You can use MongoDB Atlas with all the major cloud providers like Amazon AWS, Microsoft Azure and Google Cloud. Atlas vector search can be used for recommendation systems, question-answer systems, semantic search, synonym generation, image search and feature extraction.
For a complete tutorial on using Atlas vector search, you can check out the MongoDB blog on building generative AI applications using MongoDB.


