
Ways of Dynamic Data Masking SQL Server Fields
Dynamic data masking feature in SQL Server provides the possibilities of hiding sensitive information in the database.
In today's data-driven world, organizations are constantly dealing with vast amounts of data, making it essential to optimize data storage and retrieval. Traditional row-based storage systems have their limitations when it comes to handling massive datasets efficiently. This is where column store indexes come into play. In this blog post, we will explore the concept of data files, log files, pages, and extents, delve into the world of indexes, and then focus on the game-changing technology of column store indexes. We will also discuss their limitations and how they have evolved across different SQL Server versions.
Before diving into column store indexes, it's crucial to understand the basic building blocks of data storage in a relational database. In SQL Server, actual data is stored in data files and Log file hold all the log information that is used to recover the databases. Data stores inside these data files in the form of pages. These pages are the smallest unit of data storage and typically have a size of 8 KB.
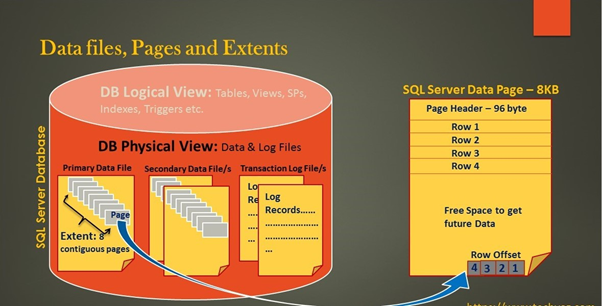
Extents are a collection of eight physically contiguous pages & are used to efficiently manage the pages.
There are 2 types of extents.
1. Uniform extent: This type of extent contains pages from a single object, either all data page or all index pages.
2. Mixed extent: This type of extent contains pages from the different objects.

An index is a database structure that improves the speed of data retrieval operations on a table. It acts as a roadmap, allowing the database engine to quickly locate rows based on one or more columns. Indexes are created on columns that are frequently used in search criteria or involved in JOIN operations.
Indexes are traditionally created using a B-tree structure, which is efficient for point queries and small to medium-sized datasets. However, for large datasets, especially when analytical queries are involved, B-tree indexes may not be the most efficient choice.
Column store indexes represent a paradigm shift in the world of database optimization. Unlike traditional B-tree indexes, column store indexes store data in a columnar format rather than a row-based format. This means that instead of storing entire rows on a page, only individual columns are stored together
Example:
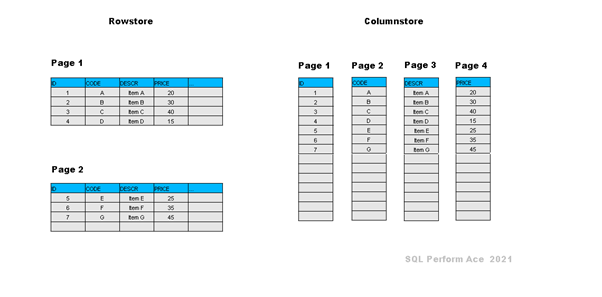
Compression
Columnar storage allows for highly efficient compression. Since similar data values are stored together, it's easier to find repeating patterns, resulting in substantial storage savings.
Improved Query Performance
Column store indexes are particularly effective for analytical queries that involve aggregations, filtering, and data warehouse operations. The database engine can scan only the columns relevant to the query, reducing I/O and improving query performance significantly which we will see in our demo section.
Batch Processing
Columnar storage is well-suited for batch processing tasks, making it ideal for data warehousing and business intelligence applications.
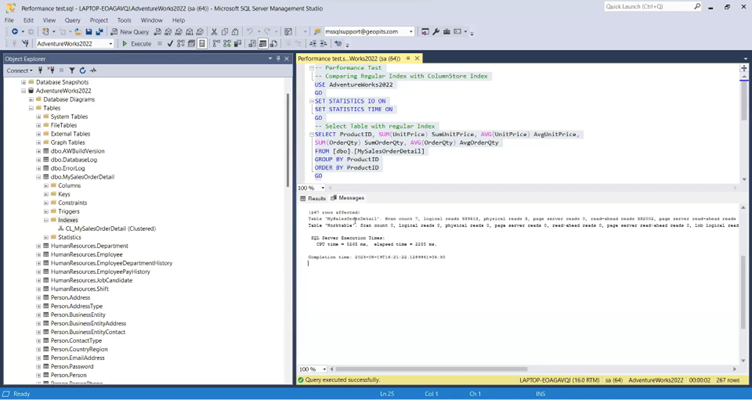
Now that we've explored the concept of column store indexes, let's put them to the test using a real-world example. We have a table named "MySalesOrderDetail" in our AdventuresWork database, containing approximately one million records. We'll perform a performance test to compare query execution before and after creating a column store index on this table.
Performance Test Without Column Store Index
• Logical Reads: 333,513
• CPU Time: 5,265 ms
• Elapsed Time: 2,255 ms
Now, let's see how the scenario changes when we leverage the power of column store indexes.
Performance Test With Column Store Index
• Logical Reads: 0
• CPU Time: 187 ms
• Elapsed Time: 59 ms
.png)
The results speak for themselves. Before implementing the column store index, our query required a substantial number of logical reads and took a significant amount of CPU and elapsed time to complete. However, after creating the column store index, the query's performance saw a remarkable improvement. Logical reads dropped to zero, and both CPU time and elapsed time were significantly reduced.
While column store indexes offer numerous advantages, they are not without limitations:
Limited Support for OLTP Workloads
Column store indexes are designed for analytical workloads and may not be the best choice for transactional databases with frequent insert, update, and delete operations.
Overhead for Small Datasets
For relatively small datasets, the overhead of maintaining column store indexes may outweigh the benefits. It's essential to assess the size and nature of your data before implementing column store indexes.
Query Tuning Complexity
Optimizing queries for column store indexes can be more complex than traditional B-tree indexes. It may require a deep understanding of how data is stored and accessed.
In conclusion, column store indexes are a game-changing technology for organizations dealing with massive datasets. Their ability to compress data, improve query performance, and support batch processing makes them an excellent choice for data warehousing and analytical workloads. However, it's crucial to be aware of their limitations and to carefully consider the nature of your data and workload before implementing them.
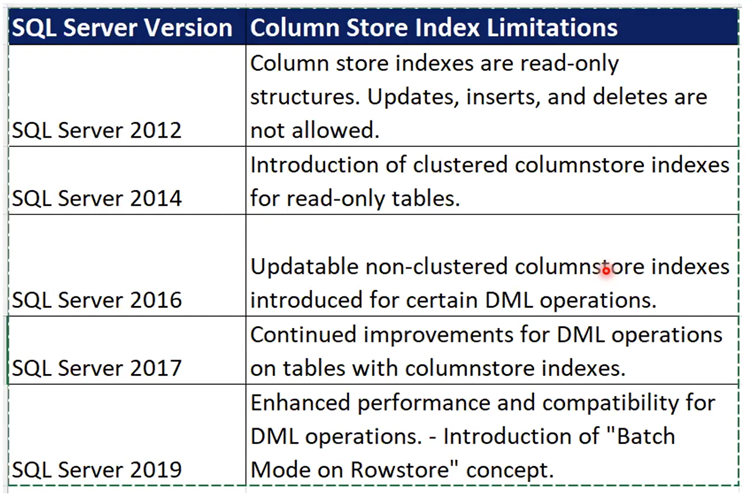
As SQL Server continues to evolve, so do column store indexes, addressing many of their initial limitations. Organizations should stay up to date with the latest SQL Server versions to leverage the full potential of this technology. When used appropriately, column store indexes can be a powerful tool for unlocking insights from massive data and driving data-driven decision-making processes.

