
In previous blogs, we have seen how we can model the data according to our business requirements and use cases. For example, we can create different collections and reference them based on a common field (usually an id field), or we can embed the fields inside a single document, as nested documents.
Once we model the data, the next step is to determine the fields that we need to extract and transform to load them into the target database. This step is also a good chance to clean up any old unused fields, and add new fields, if required. For example, let us say that in the relational database, you had two fields for the customer name, customer_first_name and customer_last_name. You want to scrap both and add a single field, namely customer_name. This step would be the right time to make those schema and design changes.
Let us discuss the different steps involved in data extraction and transformation.
Data transformation
Transformation of data involves removing unnecessary fields or data, converting to the data type as per the new schema, validation of data, data aggregation, splitting to multiple collections or joining into single collection, creating new fields as per the schema, data normalization and denormalization.
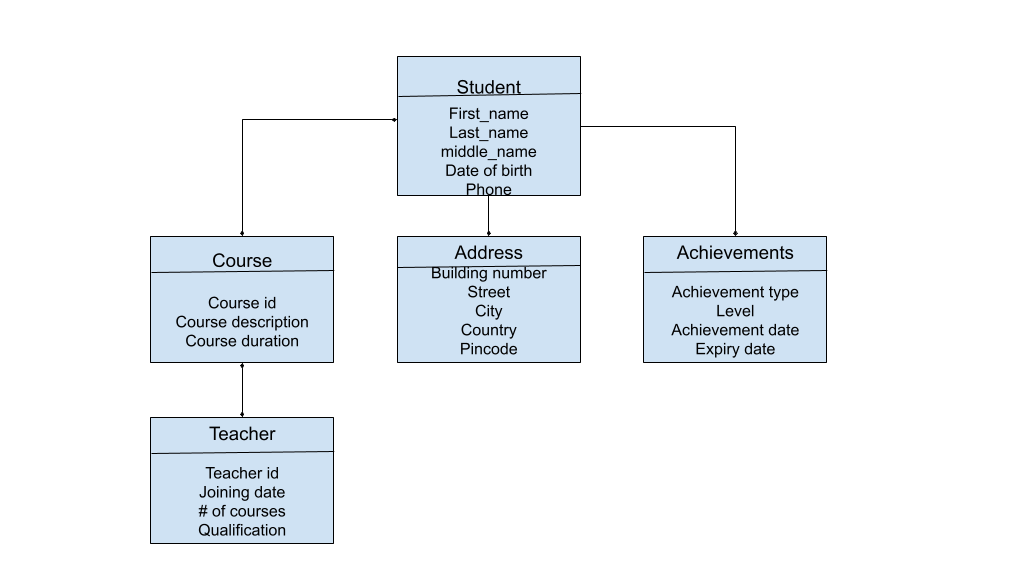
Let us take an example of a database that stores details of the courses that a student has enrolled for, including
- Student profile - name, phone, address, email, username, date of birth
- Courses enrolled along with the teacher names, timings
- Achievements till date
In a relational database, the address, course details, teacher details and possibly a few more details would be stored in separate tables. However, a non-relational database like MongoDB, would prefer storing all the details of one student as a single document that can be accessed at once. Also, consider the following cases:
- There might be data of old courses, students, or teachers, which were not deleted even if those are no longer active.
- We may want to have a field that calculates the average score of a student in all the courses that they have completed so far, to see if they are eligible for a badge or discounts on another course.
- We no longer need a separate middle_name or last_name field, we just need a single name field that contains the first, middle and last name of the student.
- We also want to introduce a new field “badges_earned”, that gets updated once a course is completed.
Each of these cases can be efficiently handled by the transformation process. For example, in MongoDB, you can add new calculated fields using the computed pattern . Also, using the aggregation framework, any unnecessary data can be removed. Similarly, the changes to the name fields can be accommodated through the schema versioning pattern, so that the data of existing students need not be changed, while the data of new students can be entered into the database with the new fields.
A rough overview of how the data (a document) might look like upon data transformation could be:
{
"schema_version":
"student_id":
"name":
"address": {
"street":
"city":
"state":
"zip":
},
"courses": [
{
"course_id":
"course_name":
"teacher": {
"teacher_id":
"teacher_name":
},
"marks":
},
........
],
"achievements": {
"badges_earned": []
},
"avg_marks": {
"$avg": "$courses.marks"
}
}
Handling relationships
The next step is to handle the relationships between data. Let us consider a simple e-commerce application, which can have many complex types of relationships.
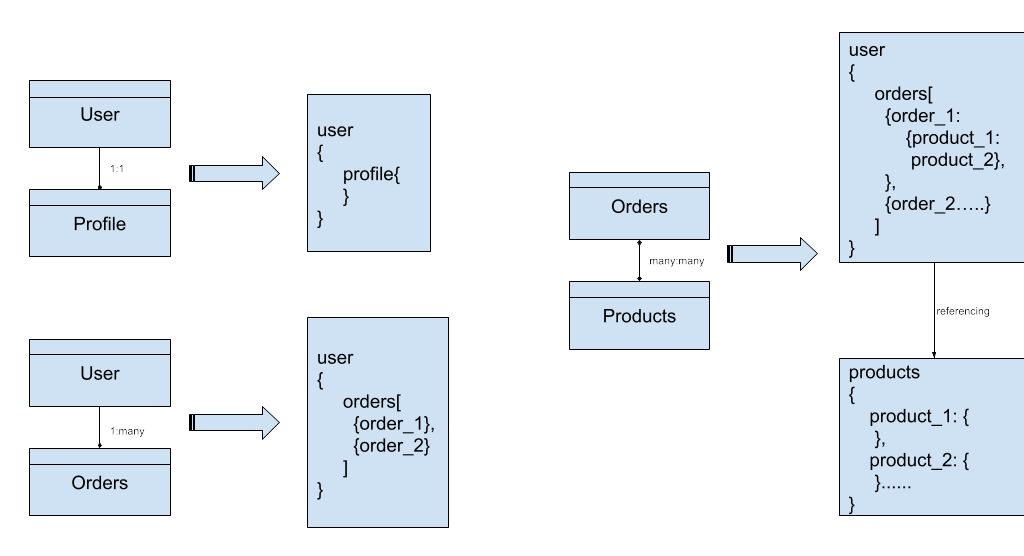
- Each user can have only one profile on the platform associated with one phone/email. This is a one-to-one relationship.
- Each user can place multiple orders on the platform. This is a one-to-many type of relationship.
- Each order can have multiple products and each product can be in multiple orders. This is a many-to-many type of relationship.
While migrating from SQL to NoSQL (let’s say MongoDB), we need to consider these mappings and accordingly decide if embedding or referencing should be preferred. In our above example, for the first two scenarios embedding would be a good option, whereas to store individual product details could make the document extremely large, hence part embedding and referencing can be chosen.
Transforming business rules and logic
The next step is to transform the application queries, adjusting the data access layer, handling the CRUD operations, ensuring data integrity and consistency and optimizing queries. The application should work as it is in terms of functionality and is expected to perform more efficiently than before. New business rules can be applied, for example, an e-commerce application could be giving discounts and offers to existing customers whose order value has exceeded a certain amount, or offering coupons to new customers to encourage more purchase, limited time offers and so on.
Let’s take a simple example of transforming a query from SQL to MongoDB:
SQL query:
SELECT orders.order_id, customers.name, customers.phone,
orders.order_date FROM orders JOIN customers ON orders.customer_id =
customers.customer_id WHERE orders.total > 2000;
The above query joins and selects all the records from order and customer tables based on the customer id, where the total order value is above 2000. Note that we are getting only a few fields like, name, phone, order date and order id and not all the fields present in the tables.
Corresponding MongoDB query depends on how your document is structured. If all the details are embedded in the same document, all the data can be obtained simply by querying the “customers” collection. If the order details are referenced, then we can use the $lookup option in the aggregation framework on the orders collection:
db.orders.aggregate([
{
$lookup: {
from: "customers",
localField: "customer_id",
foreignField: "customer_id",
as: "customer_info"
}
},
{$unwind: "$customer_info" },
{$match: {total: {$gt: 2000}}},
{
$project: {
order_id: 1,
"customer_info.name": 1
}
}
])
Migration of data
At this stage, we have enriched and transformed the data and applied any changes that our application requires. The application queries are also changed to the new query syntax, data types are set and normalization/denormalization (embedding/referencing) has been applied as required. The data is now ready to be actually migrated to the new database.
MongoDB provides a super useful tool, known as the relational migrator, that helps you migrate your SQL data to MongoDB. It helps determine and set the right data types, and hierarchy that can save you a lot of time otherwise!
You can download and install the relational migrator from the MongoDB official downloads page.
Upon installing, open your Atlas account (on browser). If you don't have one, set it up for free now. Then open the relational migrator app from your device. You will get a browser page like:
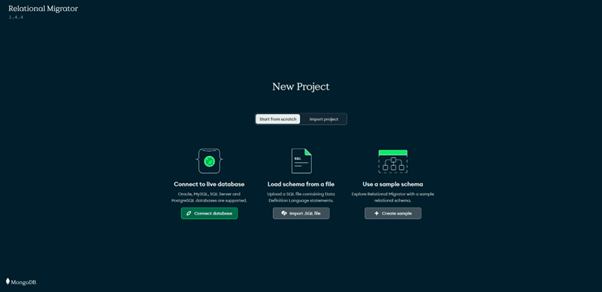
For this blog’s purpose (learning), we can use a sample schema. Once you select ‘create a sample’, the next few screens will take you through selecting the tables, defining the schema and naming the project step by step.
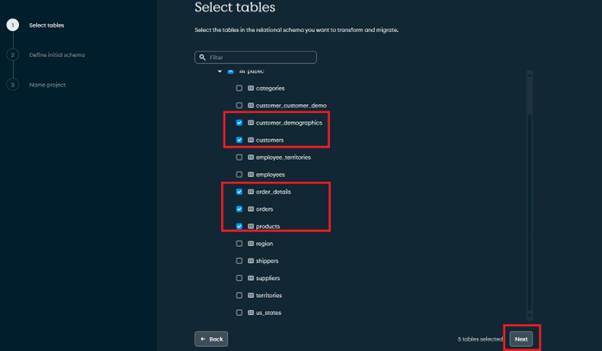
Let’s select a few tables, as shown above, and click on the Next button.
MongoDB offers you several options to choose the schema, you can select the one you are interested in and click on Next.
Option1: Start with a MongoDB schema that matches your relational schema
In this option, all the tables will be converted to collections, once you click Next.
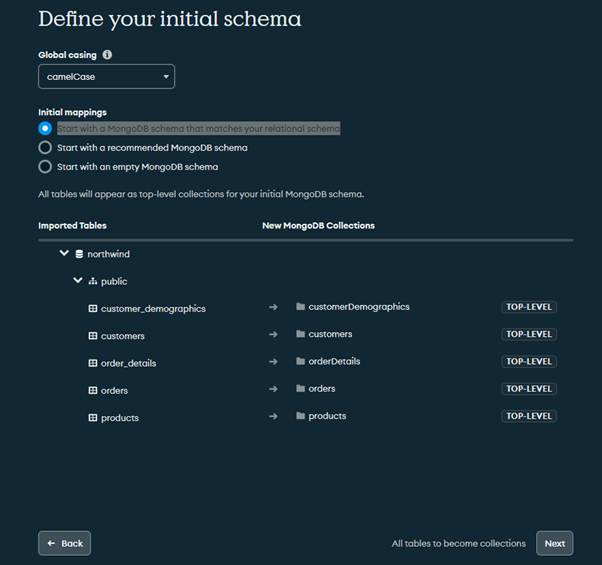
Option 2: Start with a recommended MongoDB schema
In this option, MongoDB automatically identifies the tables that are embeddable into other collections. For example, the order_details table data can be embedded inside the customers collection.
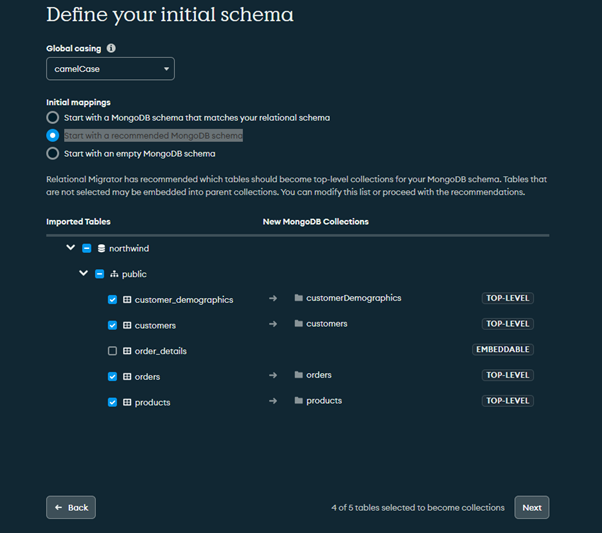
Option 3: Start with an empty MongoDB schema
The database will be blank and you can choose how you want to create your collections.
For this article, let us select Option 2 and see what happens!
Select a name for your project and click on ‘Done’.
The relational migrator shows a complete mapping of tables to collections. You can also expand on each table/collection to view the data type mapping, a few have been highlighted below:
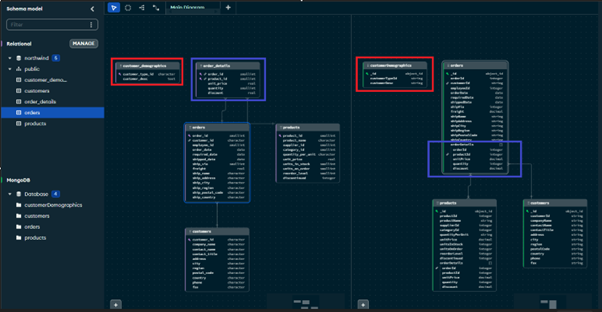
MongoDB allows you to edit the mappings, add or remove fields at this stage too.
There are many other tools available in the market for migrating to different types of databases.
Summary
In this article, we have learnt how data is extracted, transformed and migrated to the target database. We also saw a few example scenarios of the kind of changes businesses usually have to do, during the process, including changes to data type, schema, business rules, queries, constraints and many more.





