
Adding a new node to existing WSFC
This article outlines the steps of adding a new node into existing SQL Server Always On Availability Group
Unlike relational databases, that store data in a table structure, and need a schema defined before data can be loaded into them, MongoDB can accept any structure or shape of data and model it. MongoDB stores data as a document, which is the basic unit of data.
Storing data in documents makes it easier to plan data structured in application to data in MongoDB. For example, let’s consider the data is stored in MongoDB as:
|
|
Note that the structure is a set of field-value pairs. For example, the field is “_id” and the value is “1”, similarly the other fields. This structure is easy to understand for applications, and data modeling can be done similar to this in the application as well. You can model any type of data, including key-value pair, text, geospatial, time-series, graph data and more.
MongoDB consists of one or more documents, which are stored in a collection. Collection is a grouping of documents with a similar structure - not exactly the same. For example, one document can have the field ‘linkedin’, while another document need not have. However, a collection named ‘customer details’, should contain details about the customers, and not anything else. There can be multiple collections within a database. Database is the container that stores these collections.
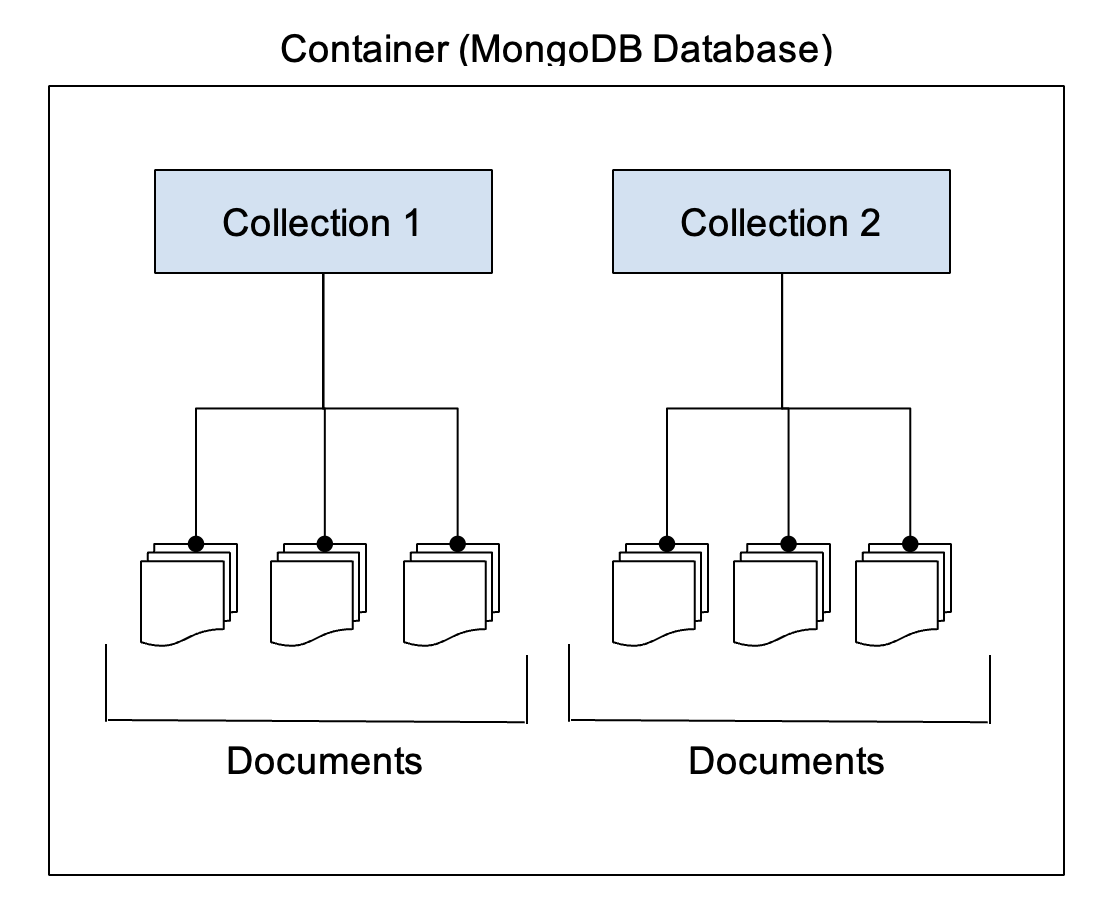
MongoDB’s document model supports two types of modeling: embedded and normalized.
In an embedded model, all the relevant data is stored as a single document in a hierarchy. For example, in the below document, address and products are embedded subdocuments inside the main document.
{user:
name: …,
address:
{location: …,
zip : …,
county
},
age: …,
products ordered:
{
product1: {product name: , description: , price: },
......
}
.....
}
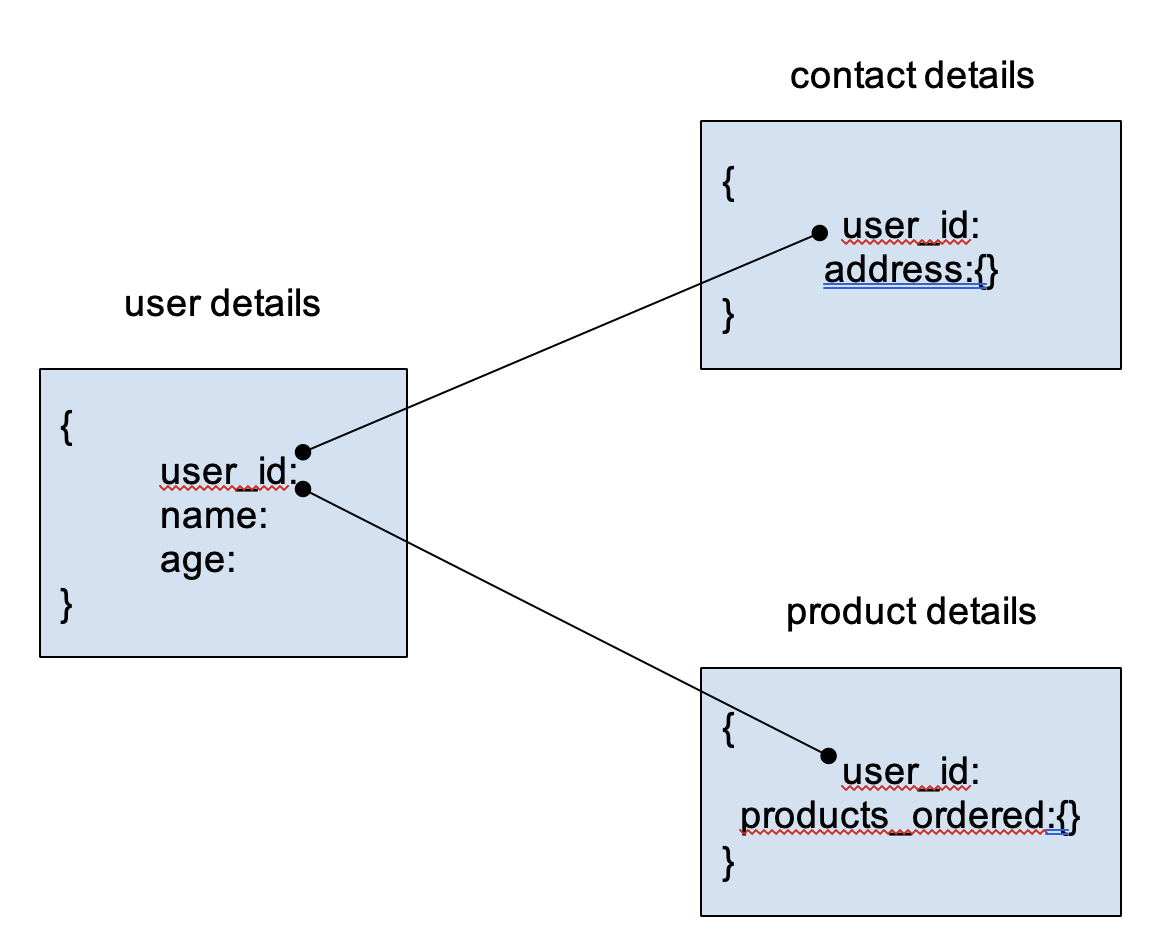
Normalized model is similar to relational structure, where relationships between documents are established using references. For example:
{
user_id:
name:
age:
}
{
user_id:
products_ordered:{}
}
{
user_id:
address:{}
}
In this article, we will refer to the embedded model for the examples.
MongoDB stores data in JSON-like format, known as Binary-SON, or BSON, which supports more data types than JSON. Therefore, MongoDB supports a variety of data types, including string, number, object, arrays, dates, ObjectId and many more. Each document can contain any number of fields with different data types i.e. polymorphic data. For example, in document 1, the field age can be a number, however in document 2, age can be a string or the field might not be present. This feature makes MongoDB much more suitable for storing huge volumes of unstructured data.
The below is allowed:
|
So, is this:
|
|
This too:
|
|
However, this does not mean that MongoDB allows any data to be stored. MongoDB provides optional schema validation rules where you can set constraints on the document structure. For example, you can set a schema validation rule on the above ‘age’ field, to accept only a number data type. You can create a validator for the specific field using the $jsonSchema operator as:
|
The document model also gives flexibility to add new fields to new documents as the data keeps increasing. For example, consider having an e-commerce website, for which you have a collection named ‘handset’ in your MongoDB database. This collection stores the handset details of all the available brands in the market as:
|
|
After the website was put to live, the website owners realized that they needed to add a handset manufacture date field too.
What’s the option with relational databases? You need to modify the schema validation script for the handset table and all the associated tables (if required) to make this change. Also, the existing data needs to be mandatorily updated to include the new field.
In MongoDB, this is not the case. You can simply insert new documents with the new field, without impacting the existing fields. The only change you would make is to your application code to include the manufacture_date field!
|
|
And yes, MongoDB provides drivers for all popular languages, like Java, Python, R, C++ and many more.
Apart from the primitive types, MongoDB also supports arrays, embedded documents and objects.
Below is an example of embedded document:
|
Here, the name field has two embedded fields, first and last. You can simply fetch the details using the dot operator. For example, name.first, name.last.
You can also create an array of embedded documents, i.e. array of objects, with any amount of nesting that your data has. For example, let’s say you want to store the different reviews of a particular movie, and review is an object having three fields namely, rating, date and text. Unlike a relational database, where you would have multiple tables storing movies, reviews, and other data, in a document model, you can have all the details inside one document:
|
|
In the above document, we can easily view all the reviews of the movie under one heading. “reviews” is an array (indicated by []) that holds multiple objects, each having their own unique _id field, and other fields.
<mongodb uses="">ObjectId, a BSON data type to store the unique identifier field “_id” by default. While inserting MongoDB documents, we can specify the value of _id field, in which case we can select the data type of the _id field. For example,</mongodb>
|
|
Note that here, the data type of _id is String. If we insert a document without specifying the id field, MongoDB will generate it with the data type ObjectId and a corresponding hexadecimal value. For example,
|
|
MongoDB _id field accepts many data types. You can add String, integer, double, boolean, binary, timestamp BSON types like ObjectId, BSONSymbol and so on. In the same collection, you can have different data types for the _id field, just like other fields, unless explicitly specified in the schema validation document.
Data modeling can be done in two ways in MongoDB, through embedded documents or normalization (referencing). Both models ensure flexible document format, where each document can have similar but not necessarily exactly the same structure. MongoDB accepts variations in the fields, without changes to the schema, unless specified in the schema validation. The flexible document model makes MongoDB an ideal choice for data-driven and data-intensive applications like content management, e-commerce, time series data, IoT, real-time analytics and Artificial Intelligence.


