
What is time-series data?
Time-series data is data captured over a period of time. This data can be ingested in the database as events happen (real-time) or at regular intervals (irrespective of whether any event happens or not).
With the advent of IoT devices, motion cameras, monitoring devices (like ECG), online stock trading, online financial transaction systems and many such time-based use cases, capturing time-series data has become quite important to track unusual activities, identify patterns, or derive insights.
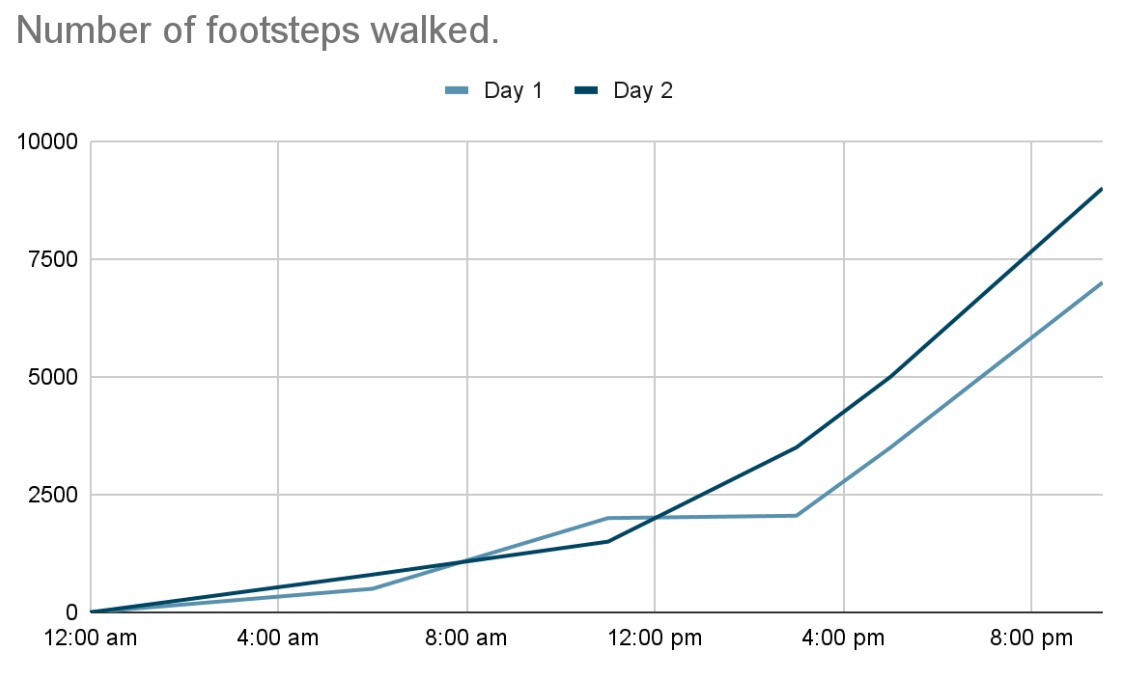
A simple example of time-series data is a fitness band that captures the wearer’s movements for the entire day, week, month and so on.

Based on the above data, analysts can get metrics like peak activity time, least activity time, recommendations to increase the number of steps and more. Based on a week’s data of time vs steps, analysts can derive patterns and detect if there are any unusual activities, for example, usually there is very less activity from 11am-3pm, however on a particular day, it is unusually high - this could be an outlier.
Usually, time series data is captured as time/date range, for example, 12am-6am, 3pm-5pm or any interval that is set for capturing the data. If a date is included, we can store the entire data, like 2024-02-02 09:00:00 to 2024-02-02 10:00:00. Based on the data collected over a certain time, usually a time-series plot is created to identify patterns.
How to store Time-series data?
There are several ways to store time-series data -
- Storing time-series data in file formats like CSV, XML, JSON, Parquet - This is the simplest way to store time-series data as they offer efficient compression. These formats are great for representing and analyzing smaller datasets.
- Time-series databases - There are dedicated databases to store time-series data. These databases can efficiently handle large volumes of incoming data that is constantly changed or updated.
You can also store time-series data in a relational database, graph database or a NoSQL database like MongoDB.
MongoDB 5.0 introduced the time-series collection, exclusively to store and analyze time-series data.
By storing time-series data in a single database, we avoid the cost of getting another database just for time-series data, and also avoid the complexities of storing large datasets into file formats. Using MongoDB, you can also ingest real-time data without any performance issues, and create visualizations and analysis using MongoDB Charts on your dashboard.
The time-series collection was introduced to accelerate developer productivity and help them analyze time-series data with ease. In addition, MongoDB stores the data sorted by time, as opposed to the natural order (for example, order of insertion), like in regular collections. It also offers improved query efficiency and reduced disk usage due to the automatic creation of a clustered index at the time of creation of the time-series collection. MongoDB is a great choice for storing time series data, as the time series data grows quite fast, and MongoDB provides automatic scaling as your data grows in volume.
MongoDB Time-series collection concepts
All you need to do is mark a collection as “timeseries” while creating it, so that MongoDB knows how to store and manage the data inside of it. Normally, any time series data would have time, measurement and some identifier of the data (source).
Let us create a time-series collection in MongoDB:
db.createCollection("weeklyStepsTracker",
{ timeseries: {
timeField: "date",
metaField: "meta" ,
granularity : "hours"
},
expireAfterSeconds : 604800 // 1 week
})
- createCollection() - This is the method used in MongoDB to create a new collection, here we are naming the collection as “weeklyStepsTracker”.
- timeseries - the keyword to indicate that the collection should be a time series collection.
- timeField - the timestamp field which specifies the date and time of the data being stored.
- metaField - the unique identifier that identifies the data series and never/rarely changes.
- granularity - the time period or interval at which data should be stored - in our example, we can track the number of steps every 3 hours, or hourly or any interval of choice.
- expireAfterSeconds: This parameter decides the TTL (time to live) of the data. Once this time exceeds, the data will be deleted clearing up space for a fresh set of data. If you do not wish to delete the data, MongoDB Atlas provides an option to automatically archive the data using the Atlas Online Archive.
From the above fields, the timeField is the only mandatory field.
How does time-series data get stored in MongoDB?
For developers, there is no change in the way time series data is stored or retrieved. However, internally MongoDB sorts the data by time, based on the unique identifier (metaField data).
Consider the following data:
# Inserting multiple documents into the collection
db.stepstracker.insertMany( [
{
"metadata": { "watchId": "H78"},
"timestamp": ISODate("2024-02-23T00:00:00.000Z"),
"steps": 0
},
{
"metadata": { "watchId": "H78"},
"timestamp": ISODate("2024-02-23T03:00:00.000Z"),
"steps": 10
},
{
"metadata": { "watchId": "H78"},
"timestamp": ISODate("2024-02-23T06:00:00.000Z"),
"steps": 500
},
{
"metadata": { "watchId": "H78"},
"timestamp": ISODate("2024-02-23T12:00:00.000Z"),
"steps": 1500
},
{
"metadata": { "watchId": "H78"},
"timestamp": ISODate("2024-02-23T09:00:00.000Z"),
"steps": 2250
}
] )
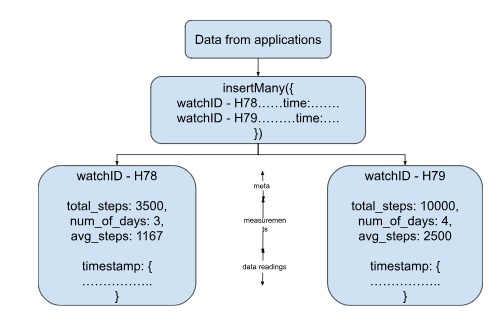
MongoDB internally will sort the data based on timestamp, irrespective of the order in which it is received. For example, in the above case, the fourth document (with time 12:00) is before the document with time 09:00 - possibly due to a network latency or some other lag. But, MongoDB sorts this and arranges the data correctly. MongoDB puts the data into several buckets of predefined intervals, making it easy to query the data. The bucketing is done using the MongoDB bucket pattern. MongoDB also stores some important facts about the data, for example, the max number of steps, average of the week, minimum number of steps, peak time of steps increase and so on, which can help in analysis and quick retrieval of relevant data.
"day_bucket" : {
"count": 5,
"min_steps": 0,
"max_steps": 2250,
"total_steps": 5000,
"week_avg_steps": 3625
},
"meta" : { "watchId": "H78"},
"data" : {
"timestamp": {
0: ISODate("2024-02-23T00:00:00.000Z"),
1: ISODate("2024-02-23T03:00:00.000Z"),
2: ISODate("2024-02-23T06:00:00.000Z"),
3: ISODate("2024-02-23T09:00:00.000Z"),
4: ISODate("2024-02-23T12:00:00.000Z")
}}
As seen above, MongoDB has separated the data into two parts - the metadata and time data. If you receive data from multiple watchIds, let's say H78 and H79, MongoDB will store the data from each watchID in a different bucket. Data from the same id (metafield) is stored in the same bucket, irrespective of the order in which they are received.
How is time-series data retrieved from MongoDB?
From a developer point of view, the retrieval is the same as how the data was inserted. The format in which MongoDB internally stores the document is not known outside of it. You can query the collection in the same way as you would query any other collection. For example, if you want to get one document:
db.stepstracker.findOne()
You can also create secondary indexes to further optimize searches and enhance query performance.
MongoDB also provides a host of aggregation pipeline operators and stages to process the data, like $dateAdd, $dateDiff and $dateTrunc. MongoDB also offers a $setWindowFields stage to perform window functions on documents.
Feature improvements in MongoDB Time-series
MongoDB 5.0 introduced time-series collection, windows functions, temporal expressions and secondary indexing on metadata. With 5.1 release, MongoDB introduced sharding support, support for delete-many on metadata and Atlas online archive support.
A major breakthrough was the introduction of columnar compression in MongoDB 5.2, which helped save disk space and improved read performance.
MongoDB 6.0 offered the capability to create secondary indexes on measurements and few optimizations on sort performance.
Conclusion
With the introduction of time-series collection, MongoDB has eliminated the need for a separate database to handle time-series data. With its rich-querying capabilities, automatic scaling, performance optimizations and many other features, MongoDB promises a great way to store, analyze and retrieve time-series data. By following simple best practices like sharding your collections and allocating more physical RAM to scale for high cardinality use cases, you can further achieve best results.





