Dynamic Data Masking in SQL Server
Dynamic Data Masking is a security feature in SQL Server 2016. This article elaborates the types of dynamic datamasking and how to use it.
MongoDB is a flexible NoSQL database that provides rich querying capabilities to get the desired results without writing extensive application code. One of the most powerful features of MongoDB is its aggregation framework, which can be applied to the data in multiple stages to produce the desired output.
MongoDB aggregation framework provides various operators that can be used in a pipeline (one after the other) to process and transform data. You can group, filter, sort, match, summarize data, amongst other operations. In this article, let us learn some widely used aggregation operators.
The aggregation framework supports multiple operations for performing complex database tasks, business intelligence, data analytics, processing and transformation, in a highly efficient and scalable fashion.
As data is critical to all the applications today, aggregation framework provides methods to summarize huge amounts of big data to identify data trends, patterns and forecasts. You can also generate reports, charts and other visualizations to summarize data.
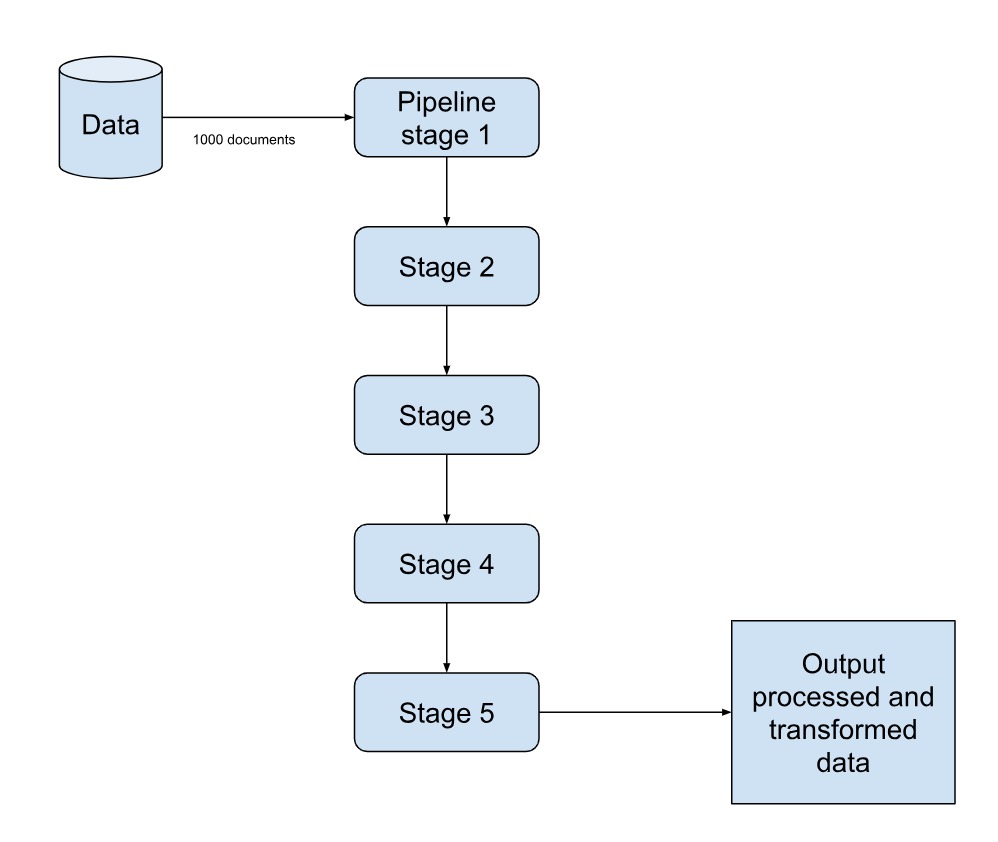
To use the aggregation pipeline, you should use the method aggregate() on the shell. The aggregate() method accepts an array of stages (operators) as the argument. Every stage is meant to transform data in some manner and pass the resultant data to the next stage. For example, if your collection has 1000 documents, and you have 5 pipeline stages, the first stage will be fed with all the 1000 documents. The result of the first stage might be more or less than 1000 documents depending on the operation performed. This result is then fed to the second, third, fourth and final stage sequentially. The final stage produces the desired output.
While using the aggregation pipeline, you can also use the same stage multiple times in the pipeline. For example, you can use $group any number of times in the same pipeline. However, $out, $merge, and $geoNear stages cannot appear multiple times. MongoDB also provides aggregation expressions to specify the operators and calculate values. For example, arithmetic expression operators like $abs, $log, $multiply, or array expression operators like $in, $map, $range and many more. You can also nest aggregation expressions.
Some important pipeline stages of MongoDB aggregation framework are:
$match: $match operator filters documents that satisfy a certain condition given in the query. Let’s say you have a movie collection and you want to list all the movies released in 1921, you can use the $match stage as:
db.movies.aggregate(
[ { $match : { 'year' : 1931 } } ]
)
$group: The $group operator groups certain items based on a group key. The group key is nothing but a field, or a group of fields. It can also be the result of an expression. Suppose you have an online grocery store and you want to group items by category. You can use the $group operator as:
db.sales.aggregate( [ { $group : { _id : "$category" } } ] )
You can also use further expressions to get the average, sum, product, range etc of the items in the category. For example, to find the total number of items of a particular category, you can use the following:
{
_id: "$category",
totalItems: {
$sum: '$quantity'
}
}
$addFields: Suppose you have a customer_order collection, which tracks your order details. Let's say you purchase item A, B and C, of value $10, $30, $40. You can calculate the total order value by adding A+B+C and assign it to a new field, say purchaseTotal. This is the purpose of the $addFields operator. It will add a new field in your collection with a computed value of the existing fields:
db.customer_order.aggregate( [
{
$addFields: {
purchaseTotal: { $sum: "$items" }
}
}
where items is an array containing the price of the items:
items: [ 10, 30, 40 ]
$sort: As the name suggests, $sort sorts or arranges the documents in an ascending or descending order, depending on the sort criteria provided in the query. For example, let us say, you want to get the customer details from the customer collection of sample_analytics database sorted by the customer name, you can use the $sort operator as:
db.customer.aggregate(
[
{ $sort : { name : 1 } }
]
)
You can also sort by multiple fields and specify the order for each:
{ $sort: { name : 1, username: -1 ... } }
Here the ‘1’ indicates that you are sorting documents from A-Z, a ‘-1’ would mean reverse order.
$unwind: In $unwind lies one of the true powers of a flexible database like MongoDB. Through this stage of the aggregation pipeline, you can deconstruct (or unwind) any array and view its content. Each of the deconstructed documents will have the same _id field for identification. Let’s unwind the contents of the products field of the accounts collection in sample_analytics database. You can view each product associated with each account_id.
db.accounts.aggregate( [ { $unwind : {
path: "$products"
}} ] )
To get the products associated with particular account_id, we can use the $match and the $unwind stage in the pipeline:
[
{
'$unwind': {
'path': '$products'
}
}, {
'$match': {
'account_id': 976027
}
}
]
$skip: The $skip stage skips the specified number of documents before passing the rest of them to the next stage of the pipeline. You can give any 64-bit positive integer as the parameter for the number of documents to be skipped. Note that skip does not modify or process the documents in any way, just reduces the number of documents passed to the next stage.
db.accounts.aggregate([
{ $skip : 10 }
]);
$lookup: $lookup provides a way to join two collections of the same database. It is a left outer join in the form of an array field, which contains the matching documents from the joined collection. Let us take the example of the accounts and customers collections in the sample_analytics database. To join these, we can use $lookup on the customers collection with the accounts collection using the account_id field:
db.customers.aggregate( [
{
$lookup:
{
from: "accounts",
localField: "accounts",
foreignField: "account_id",
as: "result"
}
}
])
There are many other interesting operators like the $limit, $facet, $count, $fill, $search. MongoDB provides exhaustive documentation on each of these with examples. You can view a complete list of aggregation pipeline stages on the official documentation page. Create your free account on MongoDB Atlas to try a few by yourself!
The MongoDB aggregation framework is a powerful tool for data analysis. You may feel overwhelmed in the beginning due to the syntax involved, however, as you start using one or more of the operators together, you will appreciate the way you can get the exact results you want, from a single query, without modifying your application code.