
As digitization continues to advance rapidly, the need for efficient data management is growing at a fast pace. Businesses collect huge amounts of data, and accordingly need huge storage space too! Once the data is stored, it needs to be cleaned and transformed - for example, you need to remove the duplicate, inconsistent and null data from the collected data, to be able to use the data effectively. Also, to analyze the data, it must be accurate and updated at all times.
Most systems today have to fetch data from multiple sources and integrate them to perform a complete analysis.
Data federation allows for a better system to manage and integrate data from multiple sources and align it into a single unified source, using virtualization techniques.
What is Data Federation?
Data federation is a part of the data virtualization framework, where you can integrate data from various data sources, not physically, but virtually. This means you do not have to create a duplicate copy of the data, but the data will have a virtual presence to give you a unified view in one place! Having the data virtually also means that you do not require any additional infrastructure setup for storage.
.jpeg)
Note that data federation is not data consolidation - there is no change in the location of data. The data continues to live in its original source, and you can create virtual instances to integrate the data sources.
Let us take an example to illustrate this. Suppose you own a restaurant chain named “XYZ” and have branches in multiple states across the country, say location A, B, C, D. Each location stores details of customers, staff, menu, inventory, revenue, as well as customer reviews in its own data store. Suppose you want to get a complete summary of data across all regions - you would have to query each of them separately, then consolidate the data, and derive the final revenue. This could be painful. There might also be multiple similar use cases, where you might want to find the total number of positive or negative reviews, maximum consumer base, inventory check or anything else. A unified view of data would help you see the complete picture at once!
.jpeg)
Advantages of Data Federation
Without data federation, you would have to store a copy of all the databases in a centralized location, like in a data warehouse. If there are any changes in the original source, those need to be reflected in the copy as well. Also, this would require multiple transactions between your application and the other data sources - including third party systems, that adds to the time and cost of the application development. Data federation eliminates this problem, and ensures that your application always gets real-time accurate data.
How does a traditional federated database work?
A federated database does not store the actual data, rather it stores the metadata of all the databases that need to be integrated. Although the user gets a unified view of the entire data, to query the database, you need to establish a connection to the datastores. A federated database splits an incoming query into subqueries and passes each query to the correct datastore. In this process, the federated database also uses wrappers to translate the sub queries into appropriate query language. For example, a MySQL database will use the structured query language (SQL), whereas a NoSQL database like MongoDB will use Mongo Query Language (MQL). The syntax of each must be formed by the federated database. The results of these queries are stored in a temporary table. The database compiles the results obtained from each data store into a single result and presents it to the query generator.
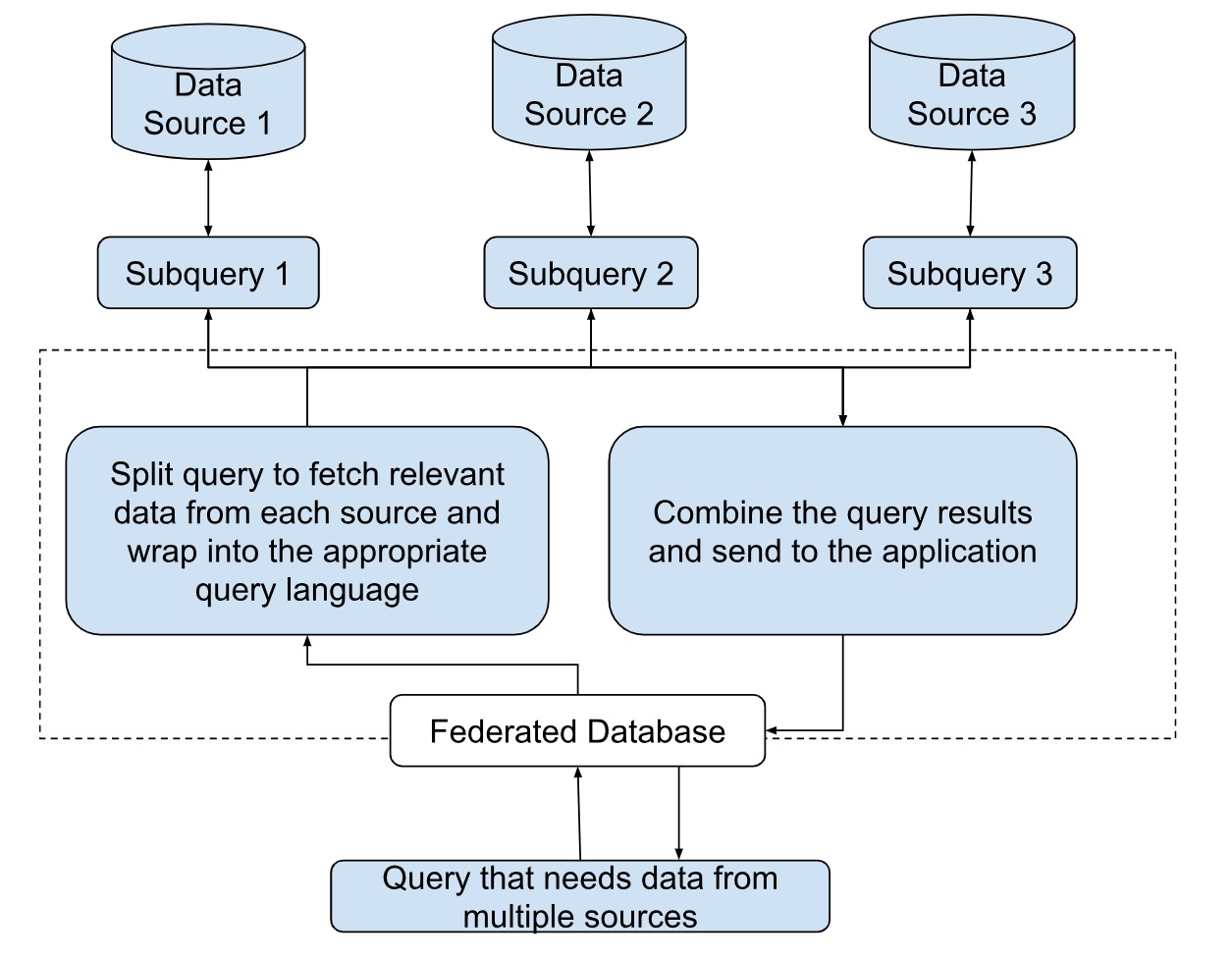
Challenges in the above architecture
Data federation surely solves the problem of getting data from scattered databases, however, application developers have to write custom code for fetching the data, create schemas, use third-party tools defeating the purpose of reducing cost and time. This is because each data source might be of a different type and can have different storage formats. To capture all of the unstructured data into a single format for display would need a lot of effort. And any changes to the original schema may have an impact on the virtual federated database as well.
How does MongoDB help with data federation?
To overcome the problem explained above, MongoDB Atlas provides a way to combine, enrich and transform data, and execute federated queries across data sources, as if the data was in a single place and in a single format. Once the federated query is executed, developers can also choose the format and location where they want the final result data to be persisted.
That’s pretty fast, efficient, cost-effective and free from custom-code!
In Atlas, you can create federated database instances that map exactly to your original data sources. This is easy and requires only some configurations to be done. Once you are done, you can use the MongoDB aggregation pipeline to transform your queries from the virtual instances. You can persist the results to any location like an Atlas cluster, Atlas data lake, AWS S3 bucket, Azure blob storage, or directly query the database and send the results to an application. You can query the data using any system like the Mongo Query Language (MQL), Atlas CLI, Charts, Data API or Atlas SQL Interface.
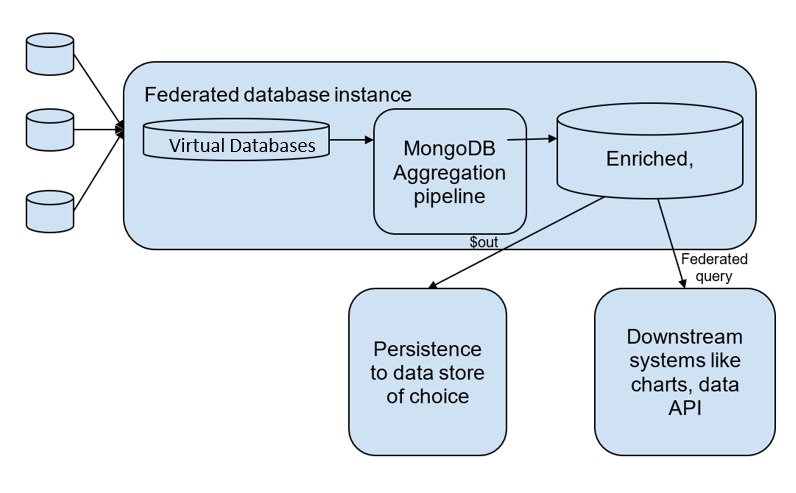
Conclusion
Data federation works on storage virtualization where multiple physical storage systems are rendered over a single cluster over a network. Federation of data saves time, cost and infrastructure resources. It also enhances security as there is no physical movement or transformation of your cloud data. If you want to try MongoDB Atlas data federation, you can create an Atlas account for free and then work with the sample data in a guided tutorial provided therein. You can connect with sample data to begin.





