
Data modeling in MongoDB is a bit different from the traditional relational databases. As opposed to the general belief that MongoDB is schemaless, MongoDB is a flexible schema database. While MongoDB’s flexible data model can accommodate any changes to the database easily and without downtime or extensive changes to the application to the database schema, MongoDB additionally provides several design patterns that can further enhance your data model to give the best results for your project requirements.
Consider a simple example, where you have a logging application that does extensive writes - let’s say 10 writes/hour. This would hit performance big time if the database is not optimized for handling writes. This is where design patterns come handy, where you can choose a design pattern and design your schema for high performance even with a high number of writes.
Choosing a particular design pattern depends on your particular use case - whether your application is going to perform more writes or reads, or the application is going to do both, what are the most common queries that are repeated in the application, and so on. Basically, you should ask the question:
“My application needs to do X, Y and Z. What design patterns would be best suited for modeling the data?”
However, there might be a trade-off in some cases, between data consistency, performance and complexity. You need to decide which one is the priority based on your specific use case - whether you need high performance and a little bit of data duplication is fine, or you have storage limits and are not much worried about nanoseconds and so on.
MongoDB provides the following design patterns, which we will discuss in brief, in this article, and cover each of them in detail, in separate set of articles:
Inheritance pattern - Group similar items together in one collection and use a discriminator field to differentiate them. For example, a “products” collection with the variable ‘type’, that differentiates the different types of products.
Approximation pattern - Store the approximate value of certain variables, where precision is not too important, instead of doing expensive calculations everytime. For example, adding a new rating may not affect the average rating of a movie.
Attribute pattern - Documents within the same collection can have different attributes in addition to the common attributes. For example, different types of products can have different attributes. A book can have name, author, price, while a laptop can have model number, price, size.
Bucket pattern - Group related documents into the same bucket based on a predetermined criteria. For example, categorizing employees into different buckets based on their experience (number of years).
Schema versioning pattern - Stores the current and previous version of a document side by side. For example, if the old schema had a ‘name’ field, and the new one has ‘first_name’ and ‘last_name’ fields, both can be viewed alongside.
Document versioning pattern - Track changes to a document over time by having all the versions of the document in the same collection rather than having a separate collection for each version. For example, tracking changes of an article at different stages - draft, technical review and client review.
Computed pattern - If a set of data needs to be computed multiple times in the application, the computed pattern can be used to pre compute the values saving memory and time. For example, calculating total order price while storing order details, so that it need not be calculated every time the user wants to view it.
Outlier pattern - To find data that does not match the other data present in a collection in specific use cases and flag them. For example, flagging unusually high valued transactions from a user, who generally does not do so.
Extended reference pattern - To fetch data from different collections into a single query, similar to the join operation in a relational database. For example, an order management application that fetches customer, order, inventory and product details for displaying it to the customer.
Preallocation pattern - When you know the document structure in advance and simply need to fill data. For example, pre-allocating a range of values for particular VIP seats in a musical event and assigning them as they get filled.
Tree and graph pattern - When hierarchical data (data with parent-child relationship) is frequently queried, it can be stored in the same manner for easy retrieval and readability. For example, organizational structure, family tree.
Let us learn a bit more about the above definitions and examples of each of the patterns.
Inheritance pattern
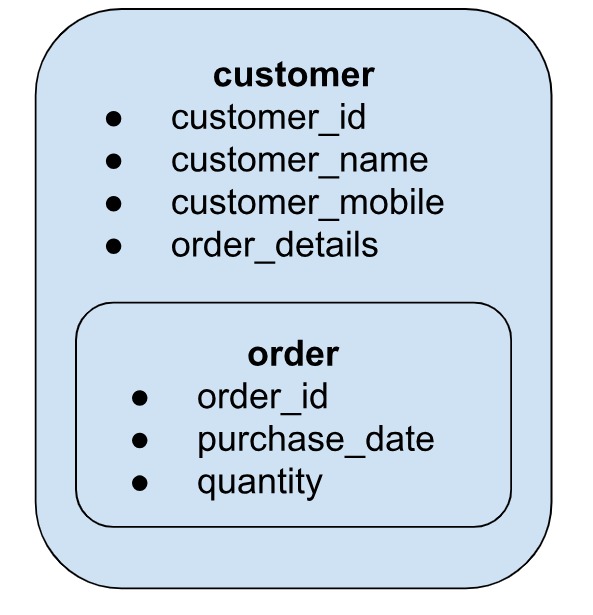
The inheritance pattern is based on the principle of polymorphism - i.e. data with similar characteristics can be stored together. The inheritance pattern, also called the polymorphic pattern, is the base for all the other patterns. It is based on the principle that “data that is accessed together, should be stored together.” This simple principle can have a great boost in the overall performance of the application. A good example of this pattern is the product catalog, where each product document can have a schema different from other but they all fall under the same umbrella - customers and orders.
Customers and orders are two different entities that are usually accessed together - for example, you need to put customer details, like name, address, mobile number in the order bill along with the order details. It might make sense to put these into the same document, rather than having separate collections and then do costly joins to access them.
Approximation pattern
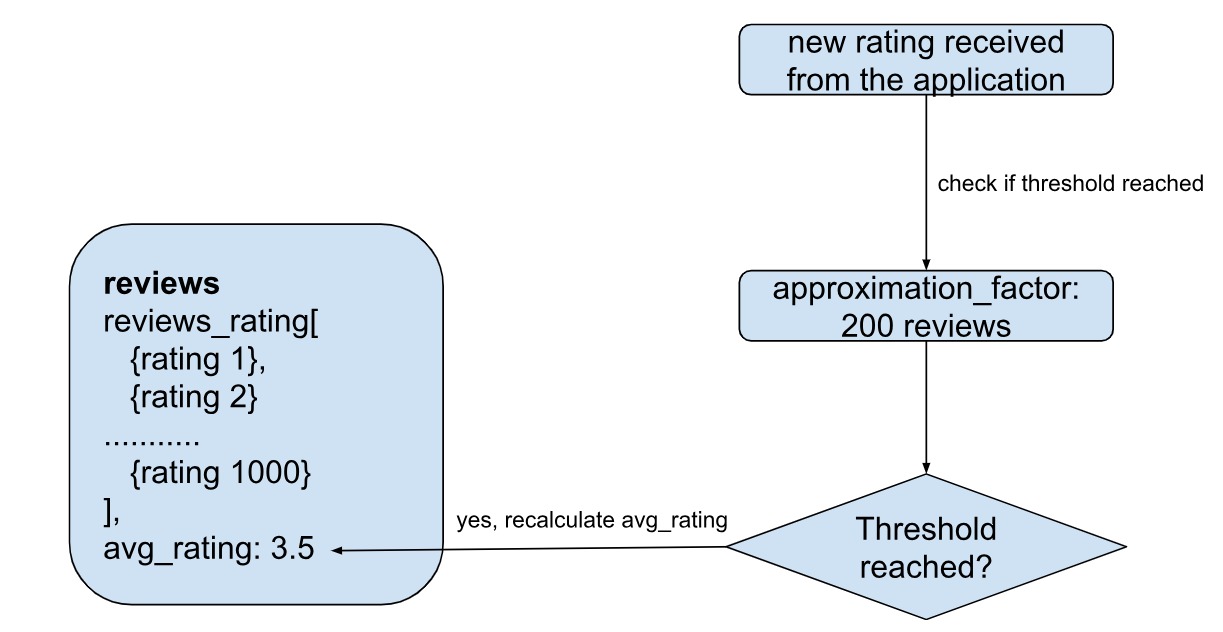
The approximation pattern is quite suitable for resource-intensive calculations that take up a lot of CPU cycles, time or memory, but an approximate computed value is enough and the application does not need exact (accurate) value. By using this pattern, we can reduce the number of avoidable writes to the database, while still maintaining accuracy of data to some extent. A good example of an approximate pattern is a review system, where a movie has about 1000 reviews with an average rating of 3.5. Let’s say a new rating is added as 4. Will the average change drastically?
No!
In that case, we can skip calculating the average rating being displayed on the screen. However, if say another 200 ratings are added into the system, then definitely there would be an impact. You can add an approximation factor, with the value of 200, wherein if the new ratings exceed 200, then the average needs to be calculated - this saves us 200 writes! The approximation factor is the maximum deviation that can be allowed before a value needs to be recomputed.
Attribute pattern
Attribute pattern allows you to have varied data types for certain fields in an otherwise structured collection. When the data has predefined fields, and mostly the fields remain the same across documents, barring a few, this pattern can be used for those exceptions.
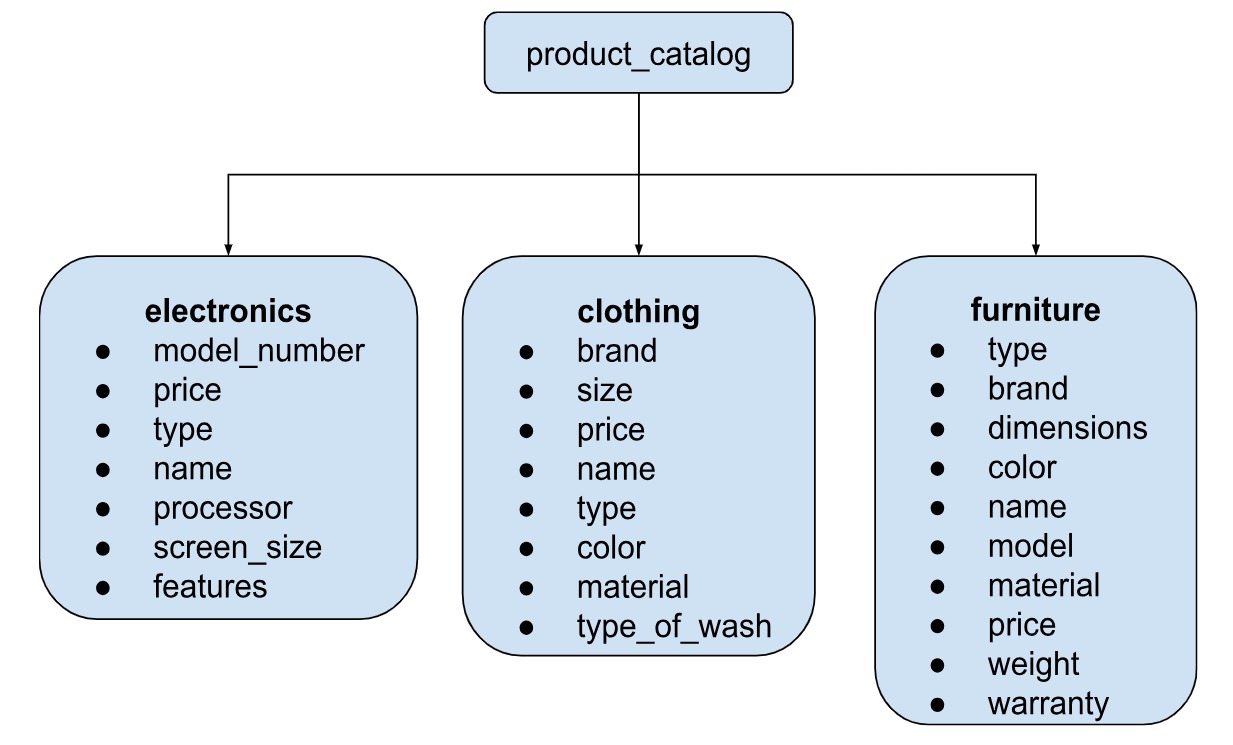
In the above example, the product_catalog collection is a vast collection with different categories of products like electronics, clothing and furniture. There are some common features like type or price, but each category also has different features (variables) of their own which are independent of the other categories. Since MongoDB has a flexible schema, it allows for the different variables in various documents inside the same collection.
Bucket pattern
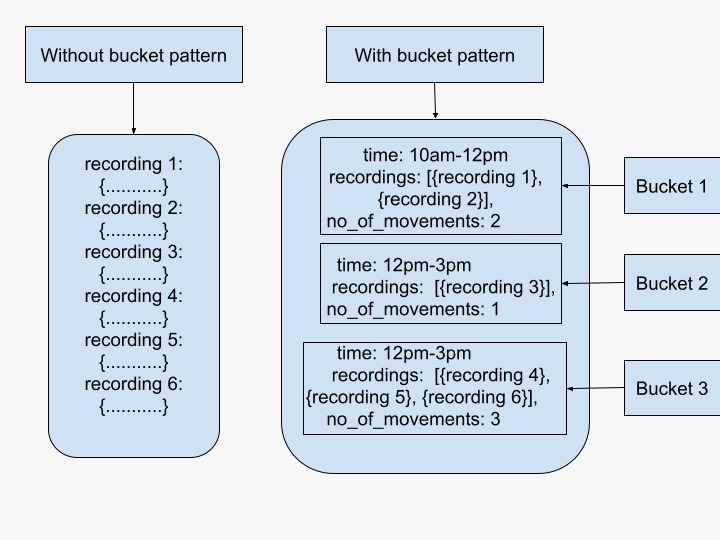
In a bucket pattern, you can group items into various buckets based on some condition. This pattern is particularly suited for analyzing real-time data, like the IoT data or time-series data. For example, let’s say you have a motion camera installed at the gate of your house that captures any movements. These can be humans, animals, vehicles or even wind. Everytime there is a motion, the camera records it and stores it. This could mean storing a lot of data and as your data grows - the index size might quickly become an issue. Instead, we can bucket - or - categorize data with a timestamp into documents with measurements of a particular time period. By this way, we can also get some aggregates on when was the peak activity around the gate and when was it lonely, and so on.
Schema versioning pattern
Any schema changes in the application requires a server downtime - at least in a traditional database. And with the ever changing data landscape of today, it is only possible that the data that we never heard of earlier, is much important to be captured and needs to be included in the database.
Whenever the schema is changed, you can include a new field schema_version in the new documents. The application can simply be updated to read the new schema and would not require any downtime too! This is only possible due to the flexible schema design of MongoDB.
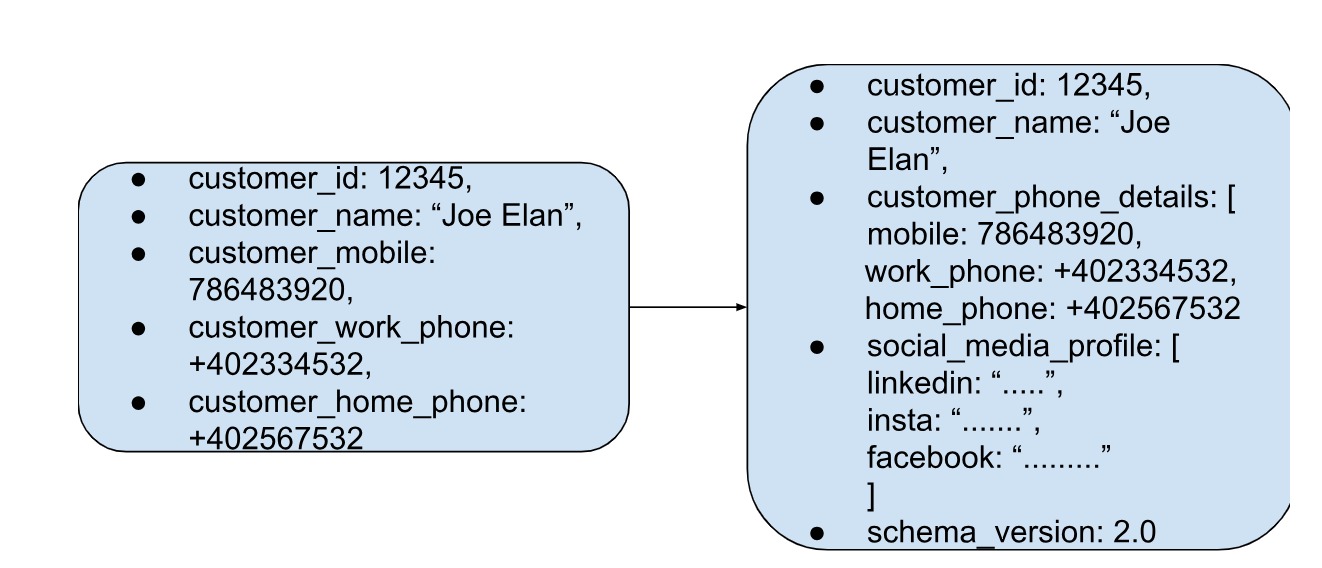
Document versioning pattern
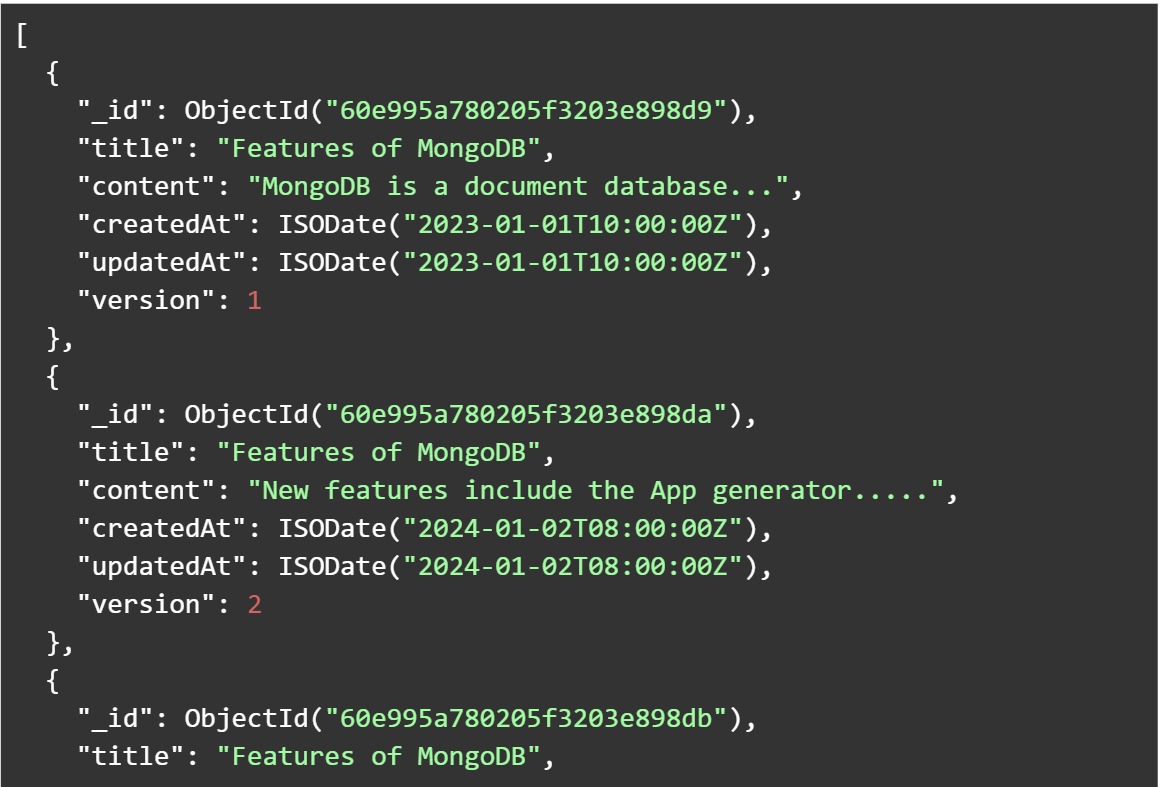
Document versioning pattern tracks changes to a document when it is modified. This is mainly to keep the older document versions as well, rather than storing them separately in a different system. Just like the schema_version field, we add a ‘version’ field to indicate the version. Maintaining a history of document versions within the same collection helps track changes to the document over time and retrieve previous versions if required. Document version pattern works well for data that is not changed too frequently. An simple example could be a blog post on Features of MongoDB which undergoes several changes as new features come up. Inside the same document, we can keep all the versions by marking them.

Computed pattern
Collecting data is much more useful if you are able to make sense out of it and perform fast analysis on fields that you know you will need - like total sales in a quarter, total inventory of products in a month, total number of views of a page in a week and so on. If your application were to calculate this data every time, that could be a lot of work for your CPU and memory. Instead, if we can do these calculations in the background, and update the main document, say once a week, or once a quarter, depending on how your application requires it, the CPU can relax.
Consider a simple example, where a customer places an order for multiple items. If we have a field named final_price, which pre-calculates and stores the total price of all the items together, we need not calculate it everytime we want to query the data. This will improve the query performance - particularly in cases where we need to display order summaries, generating reports or retrieving order details frequently.
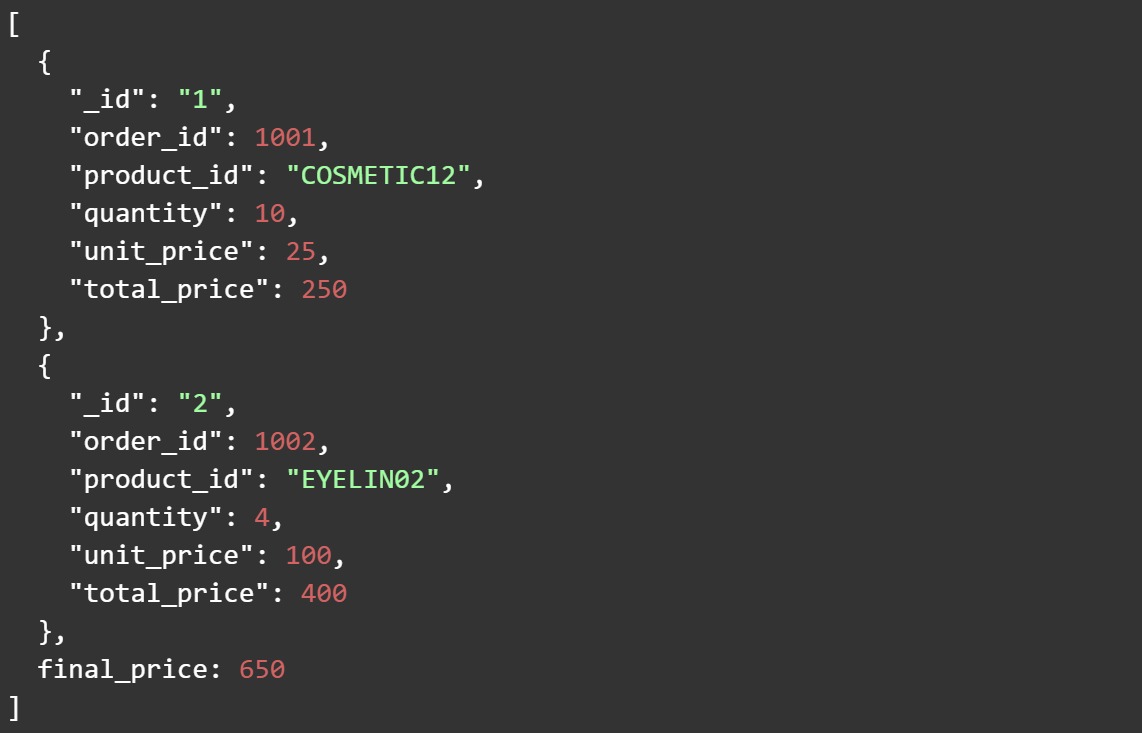
In the above example, we are pre-calculating the total_price as well as the final_price.
Outlier pattern
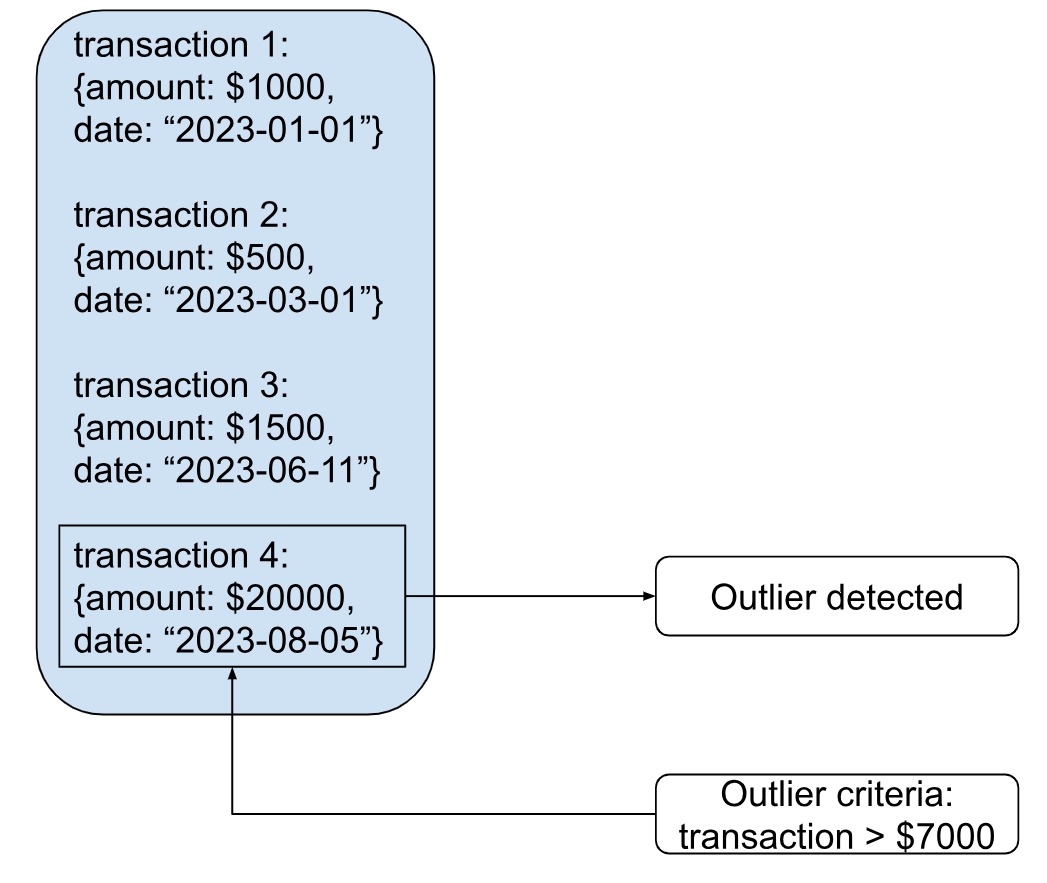
Outlier pattern helps derive more accurate insights and decisions. They can identify exceptional cases in an otherwise normal dataset. Exceptional cases could be anything like an unusual bank transaction, unusually high activity at 2am on the motion camera at your main gate, or sudden increase/drop in the sales of a product. These may require statistical methods and specific attention or processing to be addressed. For example, you can set a threshold value for a particular parameter, like a bank transaction of $15000 on an account that does not transact more than $1000 otherwise, and set a flag if the value exceeds the threshold (let’s say in our case $7000).
Extended reference pattern
In some use cases, for example, customer orders, or patient health records, we may have huge data in the same document. For example, in the case of orders, we might need to store customer information, order information, and product information inside a single document. This can cause a lot of data duplication, if you have multiple products within different documents. One approach to handle this is to create a separate product collection and then reference (join) the customer, orders and product tables. However, joins have their own set of issues and complexities.
Another approach, i.e. the extended reference pattern is to bring only the most important or most queried or data that is mostly accessed together into the same document and let the rest of it sit in the main (separate document). For example, for an order, we only need the customer_id, name, billing and shipping address and phone number. The rest of the customer details like social_media_details, date_of_birth, nationality, gender etc are not required.
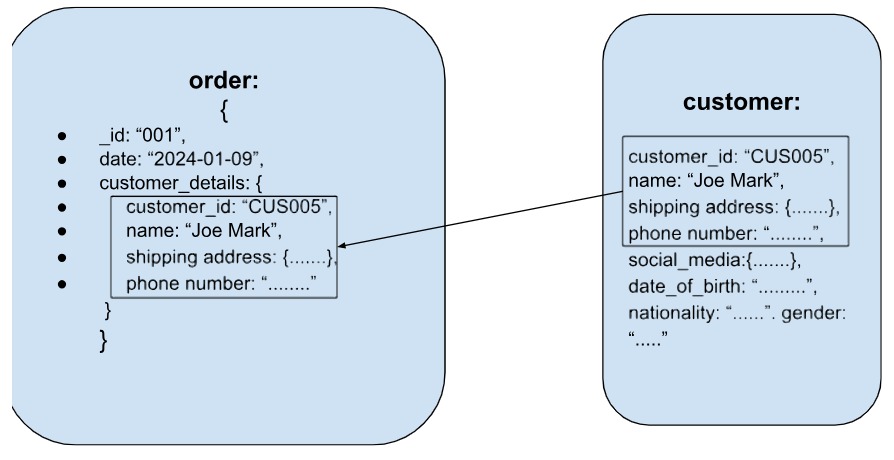
Preallocation pattern
The preallocation pattern involves reserving a predetermined set of resources or identifiers in advance, which simplifies data access and management by avoiding the need for dynamic allocation. For example, consider seating arrangements for a musical concert, where seats are categorized into different price ranges: $200 (standing seats), $500 (sitting farther from the stage), and $1000 (sitting closer to the stage). By preallocating seats within each price range, the structure of available seats is known in advance, facilitating efficient filling of seats sequentially within each category. This eliminates the need for complex calculations or traversals to locate available seats, as the preallocated structure provides a predefined framework for organizing and accessing data.
Tree and graph pattern
The tree pattern allows for efficient querying, navigation, and management of the hierarchical data. It is useful to represent any hierarchical structure, with each document acting as the node of the tree. The tree pattern works on parent-child relationship, where the parent can have multiple and nested child nodes to represent the structure. You can use it for any use case that requires a hierarchy like the structure of an organization, or, a product catalog.
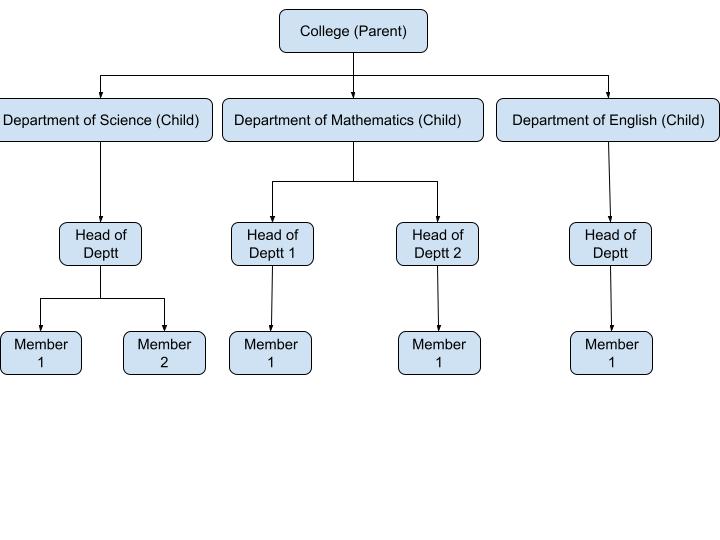
A variation of the tree pattern is the Materialized path pattern, which is also used for storing hierarchical data, but stores the complete path rather than the parent/child reference from the root to the actual document itself. For example, browsing products in a nested category (clothing->men->t-shirts->v-neck).
Conclusion
In this article, we have touched upon the various design patterns that MongoDB offers for a highly performant schema that can save you a tremendous amount of CPU cycles, memory, time and cost. You can use any of them as suited for your business requirement. It is possible to apply these patterns due to MongoDB’s flexible document structure that can accommodate a variety of data. A good schema design reduces the need for indexing the database, whereas most of the performance issues arise because of a bad schema design. You can learn more about the MongoDB design patterns from the MongoDB website.





