
If you are coming from a background of relational databases, you might be used to the rigid schema - i.e. schema once established cannot be changed, and if it has to, you need to do extensive work to accommodate the same. However, in the case of MongoDB, being a flexible schema database, there is no strict requirement that all the documents should have the same structure or schema. MongoDB follows one golden rule for data modeling:
“Data that is accessed together, should be stored together.
What is data modeling?
Data modeling is the organization or structuring of data within the database, and linking the related data entities. Data modeling is the first step of designing an application, where data can be grouped together based on the business use cases and accordingly a schema can be designed to store the data in the database.
For example, let’s say you have a website where students can enroll in one or more courses. A common way is for all the student data to be stored together, and similarly the course data be stored together. Students and courses will then be linked based on their relationship, like “is”, “has” or “contains”.

There might be other ways, for example, we can embed the most important details of the course a particular student has enrolled in, with the student data itself.
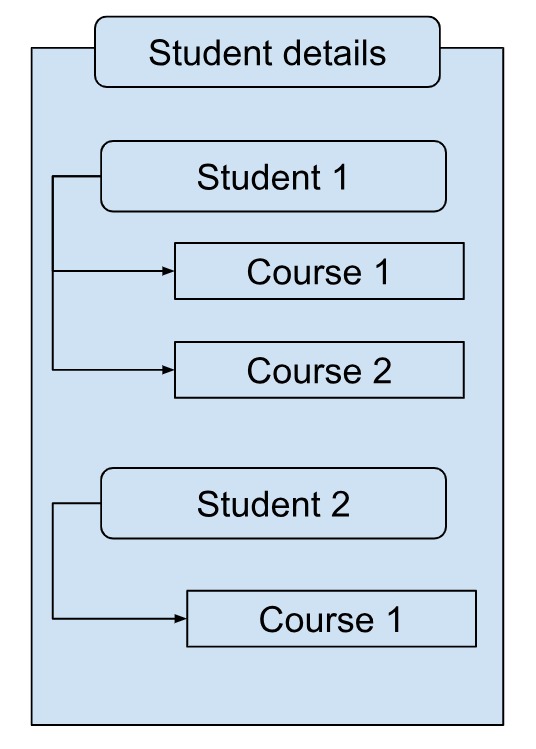
The choice of modeling depends on many factors, like the workload and business use cases of your application.
Data modeling important terms
Before moving further, let us define the important terms used in data modeling:
Normalization and denormalization
Normalization is the process of dividing the data into multiple entities based on their relationships. Each of the entities can then be referenced in the other depending on their relationship. Normalization helps to reduce data redundancy, remove data anomalies and improve data consistency. For example, in our above example, the Student and Course are two separate entities that are referenced when needed.
Denormalization is the reverse process, where redundant data is added. For example, in the second example above, we have the course 1 details in both Student 1 and Student 2 data. Although this creates data redundancy, it is helpful if we want to access the student and course details together. This would avoid multiple joins or lookups to the database.
In MongoDB, normalization is equivalent to referencing and denormalization is equivalent to embedding.
Entity
Entities are the main items that need to be modeled. Every entity should be unique. In the above example, both Student and Course are unique entities around which our application is centered.
Attribute
An entity should have a set of attributes that describe the entity. For example, a student should have a student id, name, hobbies, date of birth, skills and many other details that are relevant to the business use case.
Relationship
A relationship indicates the relationship between the various entities used in the application. For example, a student can enroll into many courses, but can have one single mentor. Similarly, one course can have multiple students.
Indexing
Indexing is essential to maintain a good performance. It is preferred to index the fields (columns) that are most used in queries, so that the search can be faster. However, indexing should be done carefully, as it comes with a cost.
Traditional schema vs MongoDB schema
In a relational database, the data dictates how you develop your application. This is because while designing the schema you would normalize your data and then as you develop your application, you may have some concerns in the way you access the data. As the database structure is rigid in a relational database, you cannot change your schema often, even if you do so, and denormalize your data, you could get into serious performance concerns.
In MongoDB, however, you can follow an iterative approach into developing and improving the data model as you develop your application. Since MongoDB offers a flexible schema, the changes to the structure of the data do not need any downtime and do not affect the performance.
For example, if you created two entities for Student and Course, and as you notice later, that teachers or admins lookup for the student data and their corresponding course data together, you can consider embedding both into the same document! To reduce the data duplication, you could add only the required fields from the course collection into the Student collection.
Data modeling in MongoDB
Data modeling in MongoDB is a three-step process:
- Workload identification - In this we identify the main use cases and entities required in the application. For example, in our student and courses app, we can have student, course, tutor, reviews as the main entities. We may get more entities as we expand on the use cases. Use cases can be anything like how many enrolments were done on a particular day, how many classes were conducted per day and so on.
- Relationship identification - Once the workloads are identified and entities are in place, we can define the relationships between the entities. There are 3 main types of relationships, 1:1, 1:many and many:many. Identifying relationships will help us understand what patterns to apply while modeling the data.
- Applying patterns - Patterns help in establishing a proper structure and best practices in the model. MongoDB has many patterns that can be used in different scenarios. Some popular patterns are the inheritance pattern, schema versioning pattern and the computed pattern.
Workload identification
As we discussed earlier, the first step is to identify the entities and attributes of the application. We have identified a few for our student-course application. Let’s say, we have the following courses - dance, music, instrument. Each of these courses will have their own attributes, like for instruments, the type - piano, violin, guitar etc. Same way, there will be professional tutors in each of these - and these tutors will have their personal information (like name, years into teaching, hobbies, other skills) as well as class details (like number of working days, time slots) and so on.
We also need to have a review system, where students can review a teacher. Same way, teachers can provide feedback about students. Review would be another entity with its own set of attributes.
Once we identify the entities and attributes, we need to quantify them -
- How many enrolments are we expecting in a year?
- How many reviews are we expecting in a year?
- How many website visits and enquiries should we expect per day?
- How many users click on the tutor feedback per day?
Based on these and more similar questions, we can estimate the reads and writes in the application. For that, we need to examine each entity and find the operations to be performed, the information needed, and the type of operation (read or write). For example, we may target about a 1000 enrolments for all the classes together in a year. That means about 83 writes per month. Same way, as the traffic grows, we may have about 1000 users looking at our website and clicking on the tutor feedback, which would mean about 1000 reads on an average day. There might be many such read and write operations, and identifying each of them will help create an efficient schema.
Relationship identification
The next step is to identify the relationship between the entities. Based on the above workload identification, we will know the details that each read and write operation requires. This will help us formulate the relationships.
For example, for a new enrollment, we need to establish the relationship between the student, course and tutor entities. Same way, for the review, we need the relationship between student, teacher and review entities.
One to one (1:1) relationship
A one to one represents one of entity A related to one of entity B and vice versa. For example, in our example, a teacher can take only one class slot at a time. So, the relationship between Tutor and ClassSlot is 1:1. This will help plan the availability of teachers during a particular time.
One to many (1:many) relationship
If entity A is related to many of entity B and entity B is related to only one of entity A, the relationship is referred to as 1:many. For example, a teacher can have multiple reviews, however one review can be for only one tutor.
Many to many (many:many) relationship
In this case, many of entity A are related to many of entity B and vice versa. For example, a student can enroll in many classes and one class can have multiple students. Similarly, a teacher can teach multiple courses, and one course can have multiple teachers too.
Let’s see all this in a summary:
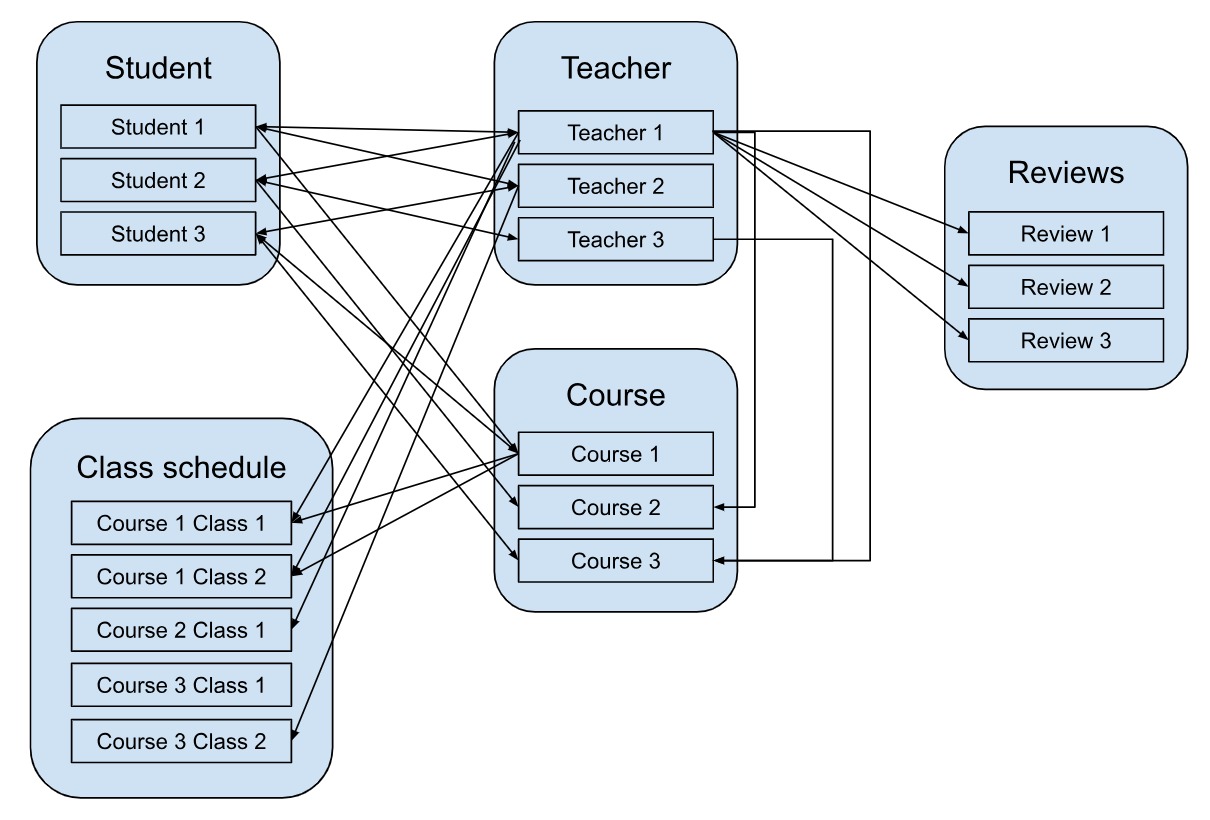
Based on the nature of these relationships, you can either embed or reference documents.
Embedding is done by creating document arrays or subdocuments. In a many to many relationship, embedding can create data duplication and it depends on our project whether we can tolerate some amount of data duplication for a significant performance boost.
Referencing is done using an array of references for child elements in the parent document or using the array of references of parent elements in the child document.
To decide whether to embed or reference the entities, MongoDB provides a set of guidelines, based on which you can answer simple questions. These guidelines include simplicity, relationship b/w the entities, archival, document size, individuality, update complexity, query atomicity and so on. for example, let us consider the relationship between the teacher and review entities -
Simplicity - Would your code be simple if the teacher and review entities are kept embedded? - yes.
Document size - would it become too huge and unmanageable if the entities are kept together - no? - however, if we are expecting reviews in 1000s then we may consider a yes.
Is the relationship between the teacher and review entities 'has a' or 'contains' - yes
Does the app query the information together - yes - a user would most likely like to see the reviews along with the teacher details
- Simplicity - Would your code be simple if the teacher and review entities are kept embedded? - yes.
- Document size - would it become too huge and unmanageable if the entities are kept together - no? - however, if we are expecting reviews in 1000s then we may consider a yes.
- Is the relationship between the teacher and review entities 'has a' or 'contains' - yes
- Does the app query the information together - yes - a user would most likely like to see the reviews along with the teacher details
In this way, we can refer to each guideline and decide whether to embed or reference. In general, you would embed the entity in the same document level or create a sub document.
In referencing, you would have separate entities that can be referred using a common unique key:
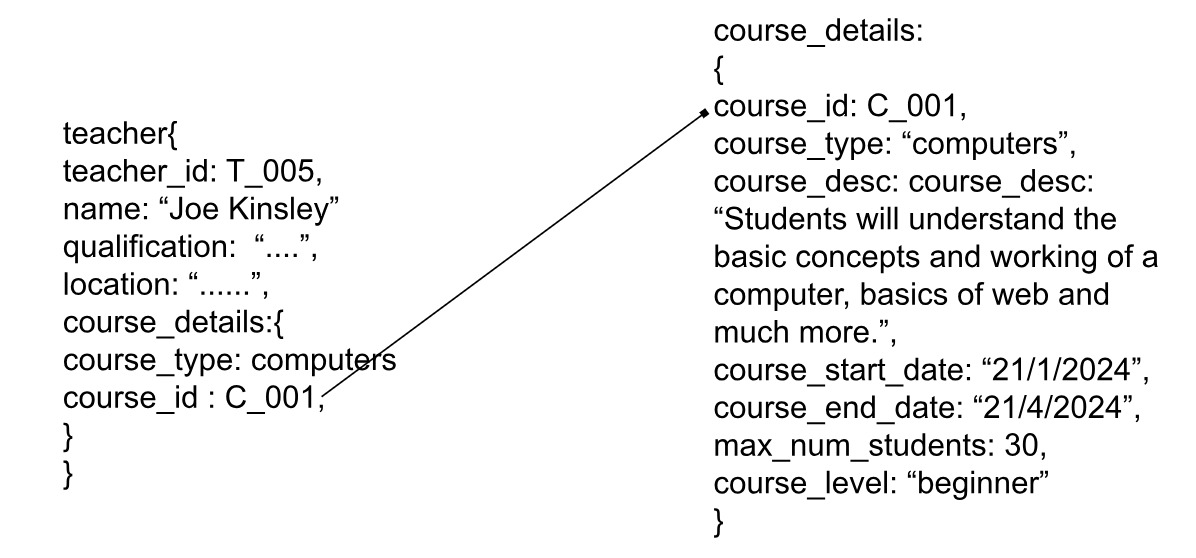
The above is a unidirectional referencing. If we also add teacher_id in the course entity, we will get a bidirectional referencing:

Applying patterns
The last step is to collate all the information we gathered in the previous steps and apply the relevant schema patterns. MongoDB provides many patterns, few of which are highlighted below.
1. Inheritance pattern - Polymorphism is a key feature of the document model of MongoDB.
The inheritance pattern is based on this principle, where you can group similar documents together in one collection. This, as we learnt earlier, is one of the golden rules of MongoDB "Data that is accessed together should be stored together."
You can use the MongoDB aggregation framework to apply inheritance pattern to existing collections.
2. Computed pattern - This pattern precomputes certain fields before the read operation. For example, calculating the avg review of a particular tutor, calculating monthly sales. We can do this using the aggregation framework. Whenever data changes, these operations can be performed and result is stored in a document for quick reference,
3. Approximation pattern - This pattern is used when data is expensive or difficult to calculate, and getting the exact result is not critical. The pattern is very useful for big data calculations and helps reduce resource usage by reducing numbers of writes and updates, when not needed.
4. Schema versioning pattern - This pattern allows you to update the schema of a database without any application downtime. This feature is a big distinguisher between relational databases and MongoDB, as relational databases allow only one schema per database or table,whereas in MongoDB you can have multiple schemas for the same database.
For a complete list of patterns, do check the official MongoDB blog, Building with patterns.
Summary
In this article, we discussed the important concepts of data modeling in general, and with MongoDB. As MongoDB provides a flexible schema, you can change the data structure as your application grows. This is a great feature because most of the data today is unstructured, which means we cannot keep a rigid structure, rather the structure evolves over time, based on our project needs. To learn more, you can also read MongoDB Schema Design Best Practices | MongoDB.





