
Configure Quorum on non domain environment
This article outlines how to configure Quorum on non domain environment
A big part of unstructured data comes from videos, large texts, files, audios and images. These are all huge in size and require more space for storage. In this article, we will learn how MongoDB stores and retrieves data as large in size as these, using an important feature called GridFS.
As we know, MongoDB stores data in BSON format, which has a limit to store only up to 16MB data. The reason behind this is to avoid a single document taking up too much of RAM or over-use the bandwidth during a transaction.
This is where GridFS comes to the rescue. To store data above 16MB, the GridFS API divides the data into smaller sizes, called chunks. While retrieving, the chunks of data can be combined to get the same data. Each chunk is a binary representation of that part of the data file.
As we know, MongoDB stores data in BSON format, which has a limit to store only up to 16MB data. The reason behind this is to avoid a single document taking up too much of RAM or over-use the bandwidth during a transaction.
This is where GridFS comes to the rescue. To store data above 16MB, the GridFS API divides the data into smaller sizes, called chunks. While retrieving, the chunks of data can be combined to get the same data. Each chunk is a binary representation of that part of the data file.

MongoDB uses the GridFS bucket fs, to store two collections for storing the files, i.e., files and chunks. The collections are identified as fs.chunks and fs.files by default, although you can change the names, and also create more buckets.
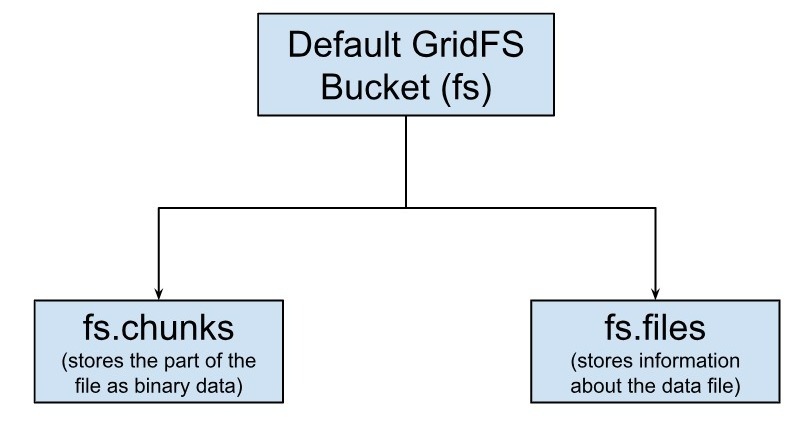
Each chunk of data is stored as a separate document in a collection named ‘chunks’. MongoDB provides each document with a default unique identifier, amongst other fields. This is a very important feature, as you can retrieve a part of data if you wish to, instead of the complete data. Only the part of data that you want is then loaded into the memory, thus enhancing the performance and efficiency of the system.
Well, in that case, you can also use GridFS to store files, which may be less than 16MB, but you still want to split the data and retrieve only parts of it as required, to save memory.
Except for the last chunk, each chunk of data should be a maximum of 255 kb in size.
Let us see the example of a document stored in the fs.chunks collection:
|
|
The _id field here is the unique identifier for the particular chunk of the file. The files_id represents the actual file, the name of which is associated in the fs.files collection. The number ‘n’ represents the position of the chunk in the entire file, and is in sequence from 0 to n-1. ‘data’ represents the actual chunk of data stored in the particular document.
Note that these are created by MongoDB by default, and you can add more fields to specific documents, for example you can add additional metadata to only some of the documents. This is possible because of the flexible schema of MongoDB.
So, how do we know which chunk belongs to which file?
For this, MongoDB provides a collection named ‘files’ that stores data about the files, i.e. the metadata. This collection stores all the relevant information about the file that is stored.
An example is given below:
|
|
The _id field is the unique identifier for the file. The length field represents the total length of the file. All the fields give important information about the original file stored in the database. You can check the complete list of fields in the MongoDB official documentation page. As MongoDB offers a flexible schema, you can also add additional fields, similar to the fs.chunks collection and give any other specific information.
There are two ways to access GridFS, the MongoDB driver and the mongo shell command line database tool mongofiles.
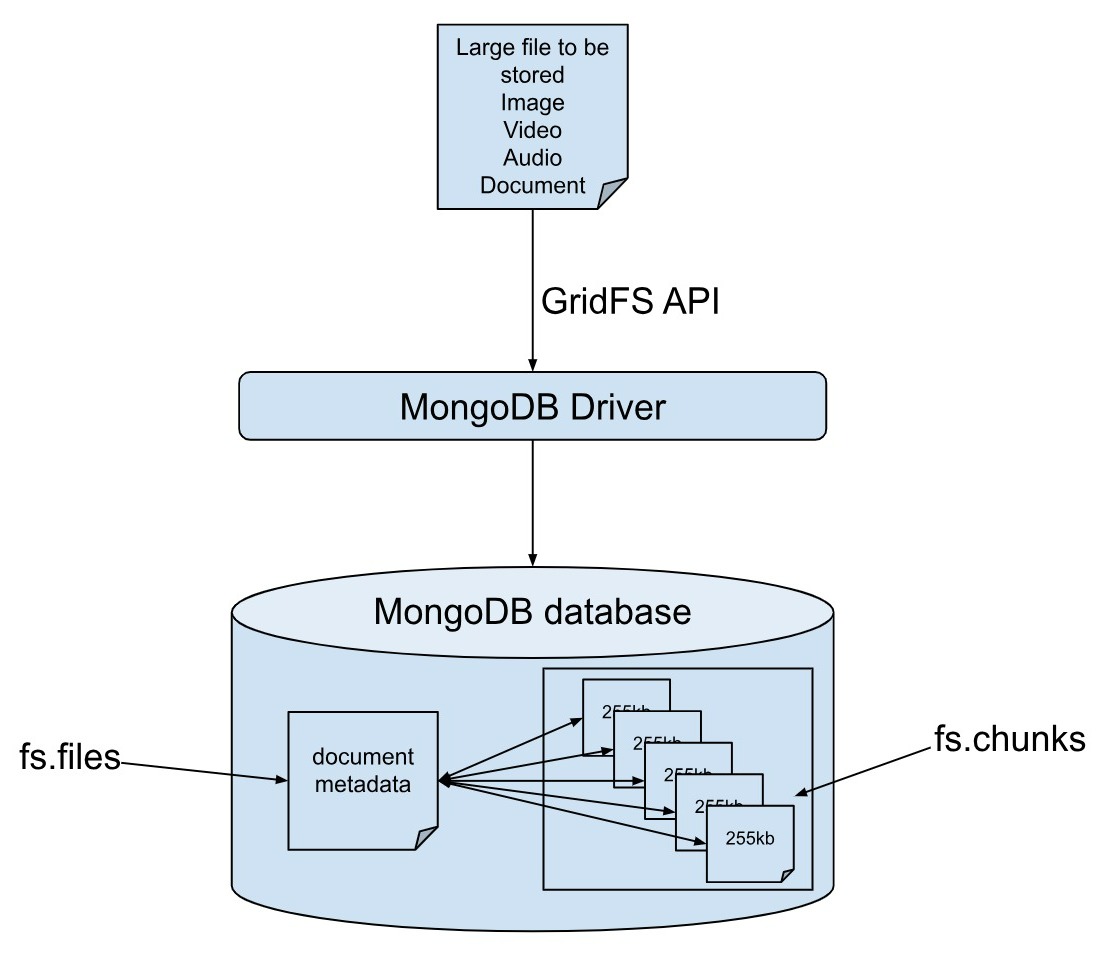
For your applications to be able to directly insert, update, and read large files, MongoDB provides drivers for various languages. Note that the entire work of sizing down the data file into chunks while storing and combining all the chunks during retrieval is done by the GridFS API and the developers just need to write the code to pass the file along with the necessary parameters, including the metadata, by opening a new GridFS bucket and using the upload_from_stream() (or similar method depending on the language) to store and open_download_stream() (or similar method depending on the language) to retrieve the file.
You can also remove a particular by using the delete() method and passing the _id field. To delete the bucket itself, i.e. the chunks and the files collection, use the drop() method.
If you want to manipulate files from a command line interface, you can use the mongofiles tool and type the necessary commands and options. To use the mongofiles tool, download it.
You can copy the downloaded database tools folder to the bin folder of your MongoDB installation.
You can then shoot commands to the MongoDB database from the bin folder in your command line interface by using the mongofiles.exe executable.
For example, to insert a file into database using GridFS, use the below command:
>mongofiles.exe -d mydatabase put document_model.pdf <meta charset="utf-8" />
This will create two collections in the database, namely, fs.files and fs.chunks. You can view the collections using the show collections command. If you want to view the data in the files collection, use:
>db.fs.files.find()
Using the files_id field, you can also get the data in the chunks collection:
>db.fs.chunks.find({files_id:ObjectId('223a75g19l94bxel8p2ef32y')})
This will give a list of the ‘n’ documents created for storing the file. If you want to fetch a particular document, you can do so by using the _id field. This helps you fetch/skip certain parts of the file, while still getting the other parts intact.
GridFS API provides methods that make it easy to store large files. Once you upload data via memory or stream, GridFS internally divides it into chunks of binary files, and stores it into a default collection named fs.chunks. It further creates fs.files, which stores information about the file, i.e. the metadata. Note that these two collections are created by MongoDB, if they don't exist.
You can create any number of fields and add more information as required into some of the documents of both collections as required. While inserting data, GridFS checks for the MD5 checksum to ensure that the chunks belong to the same file.
It also creates default indexes to ensure the efficiency and speed of the assembly and retrieval of the binary documents.
GridFS creates a compound index on the files_id and n fields of the fs.chunks collection. The files_id field helps to quickly get all the chunks associated with a file, and the value of n allows to sort the chunks as per sequence. On the fs.files collection, GridFS uses a compound index on the filename and uploadDate fields.
Apart from this, you can also create indexes on other fields as per your application needs to further enhance the speed of document retrieval.
MongoDB driver creates the GridFS bucket only for the first write operation, if the bucket does not exist. The same applies for the index - if there is no index on the collections and the bucket is empty, the driver creates indexes.
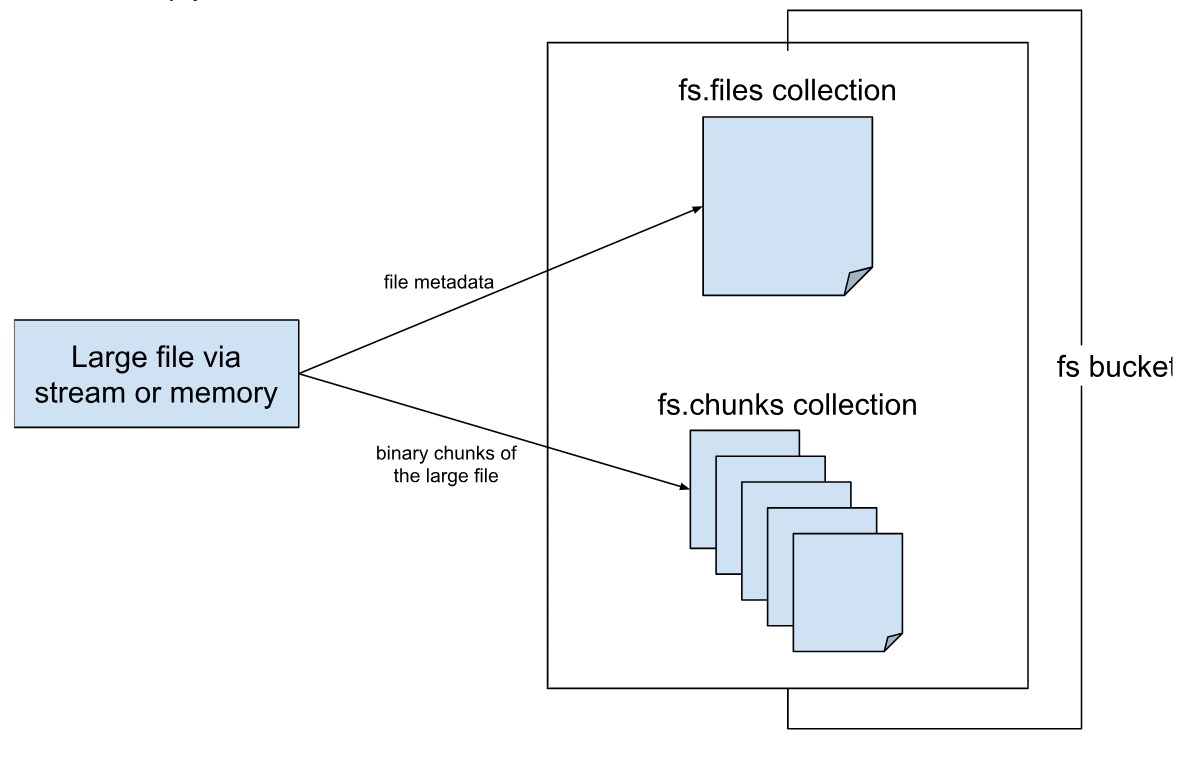
The fs in our references implies ‘file system’ i.e. the buckets and collections created by the file system by default. As we mentioned in the previous section, you can create your own custom bucket and name it something other than fs too.
const bucket = new mongodb.GridFSBucket(db, { bucketName: 'custombucketname' });
In a distributed environment, where data is stored into multiple clusters, sharding plays an important role in scaling the database and retaining the efficiency of writes and reads. You can shard both the files and the chunks collections individually. You can use Hashed sharding on the chunks collection or use { files_id : 1, n : 1 }; or { files_id : 1 } as the shard key index. The files collection is relatively smaller and if you choose to not shard the files collection, the data will live on the primary shard.
It is important to note that GridFS provides a simple way to store all types of data into a single repository. This is the major benefit of using GridFS. Other important benefits are:
You can add any number of fields to the collections, allowed by MongoDB’s flexible data structure, and also get certain parts of the data, skip the retrieval of certain parts of the data, which further enhances the flexibility
High availability and sharding (scalability) features of MongoDB can be used for all the types of data - unstructured and structured, making the application architecture quite simple to understand
Streamlined security mechanisms for access control and data security
MongoDB also provides the flexibility to create custom indexes for efficiency of data querying.
In today’s digital world, we consume and generate a lot of data, and to be able to store and retrieve data could quickly become a bottleneck, if not for the efficient mechanism provided by MongoDB in the form of GridFS. However, if you store extremely large files (of several gigabytes) in this way, your application’s storage requirements may increase and result in a performance overhead. Before storing your files in GridFS, you should carefully consider the implications - for example, if you want to access parts of large files, but without loading the complete file - using GridFS makes perfect sense. Similarly, when you want to keep your files and metadata automatically synced and deployed across a number of systems and facilities, you can use GridFS.


