
Introduction to MongoDB Indexing
MongoDB indexing is the secret sauce that transforms the database from good to exceptional. This article serves as a gateway to understanding the profound impact of indexing on MongoDB's performance. We'll delve into the core principles, unraveling why indexing is not just a feature but a critical strategy for elevating the efficiency and responsiveness of your MongoDB database.
From accelerating query performance to optimizing resource utilization, indexing becomes the backbone of a high-performing MongoDB database.
As data scales, so does the challenge of retrieving information swiftly. Indexing plays a key role in mitigating the impact of size on query speed.
Indexing transforms the way MongoDB retrieves information and stores new data, fostering an environment where data flows effortlessly, ensuring both reading and writing occur at optimal speed.
Understanding MongoDB Indexing Mechanisms
MongoDB Uses B-Tree data structure for Indexing. Let’s consider a real-world example. Imagine a bustling company GeoPITS where DBAs and data engineers are in high demand. Picture a specific query aimed at finding experienced Data Engineers.
We'll dissect the query:
db.employees.find({"Domain":"Data Engineer","year_of_experience":{$gte:2}}),
and its corresponding B-Tree index based on Domain, Experience. MongoDB harnesses the power of B-Tree dat a structure for unparalleled query efficiency and transforms complex queries into seamless, lightning-fast operations.
Syntax: db.employee.find({"Domain":"Data Engineer","year_of_experience":{$gte:2}});
Query: Domain:1, Experience:1}
B-Tree Diagram:
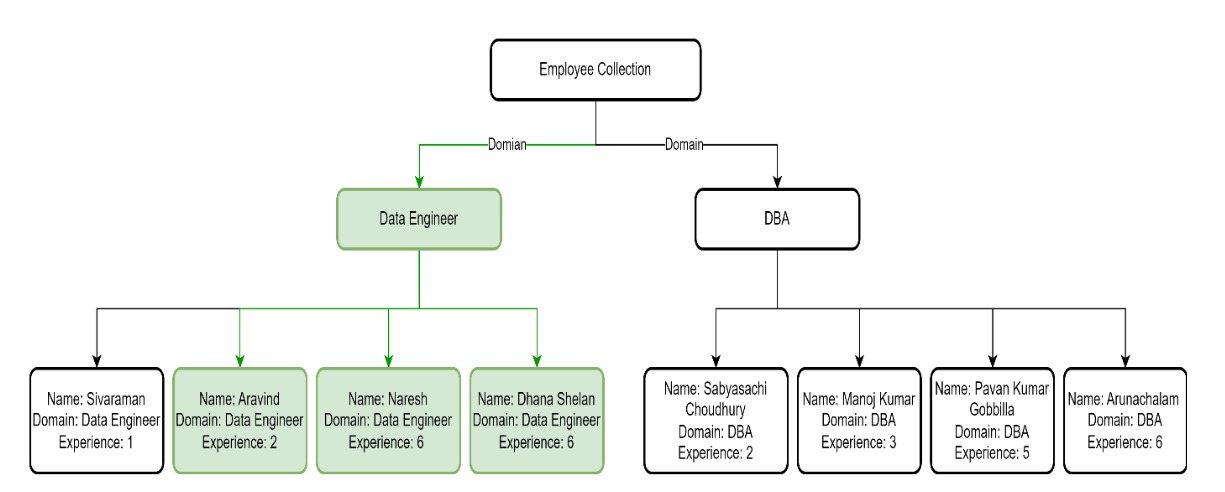
Now, for enhanced clarity, let's introduce a visual cue in our B-Tree diagram. The boxes representing the selected criteria, such as Domain with "Data Engineer" and Experience with a value greater than or equal to 2, are highlighted in green. This color-coded indication provides a clear visual representation of how the B-Tree efficiently navigates the index, showcasing MongoDB's ability to optimize and execute complex queries with precision. Witness the synergy between the query conditions and the B-Tree structure, where green signifies the specific criteria selected by the MongoDB query engine for optimal results.
Common Types of Indexes in MongoDB
Single Field Index:
Explanation:
MongoDB's Single Field Index is a fundamental tool that optimizes query performance by honing in on a specific field within your documents. This indexing approach significantly speeds up retrieval for queries involving the indexed field. Imagine a scenario where you have a MongoDB collection of "employees," and you frequently run queries to find employees based on their "designation." Creating a Single Field Index on the "designation" field ensures swift query responses, making it ideal for scenarios where certain fields play a central role in your data retrieval needs.
Use Cases:
- Accelerates queries that filter or sort based on a specific field, such as "designation."
- Enhances the efficiency of searches for unique values within the indexed field.
- Optimal for equality and range queries related to the indexed field.
Example: Creating and Implementing Single Field Indexes:
Consider a MongoDB collection where you manage information about employees. You often need to find employees based on their "designation." By creating a Single Field Index on the "designation" field, you can significantly boost the speed of queries related to employee roles. Let's explore the step-by-step process of creating this index, ensuring that your MongoDB queries for employee designations become not only faster but also more efficient.
Syntax: db.Collection_Name.createIndex({Field:1});
Query: db.employees.createIndex({designation: 1});
Multikey Index:
Definition and Significance:
MongoDB's Multikey Index is a powerful tool designed to handle complex data structures, particularly arrays and nested documents within a field. This type of index is crucial when dealing with scenarios where a field contains arrays, and you need to optimize queries related to the elements within those arrays. Imagine a MongoDB collection storing information about blog posts where each post has multiple tags. Creating a Multikey Index on the "tags" field becomes significant as it allows for efficient querying based on individual tags within the array.
Significance:
- Essential for optimizing queries involving fields with arrays or nested documents.
- Allows MongoDB to efficiently index and retrieve information from within arrays.
- Perfect for scenarios where a single field contains multiple values or subdocuments.
Scenario-Based Applications:
To grasp the practical application of Multikey Indexing, let's consider a real-world scenario. Picture a MongoDB collection storing data about books, where each book document includes an array of authors. If you frequently run queries to find books based on a specific author, creating a Multikey Index on the "authors" field becomes instrumental. This example will guide you through the steps of creating this index, showcasing its significance in optimizing queries that involve searching for books by individual authors.
Syntax: db.collection.createIndex({ "field_with_array": 1 })
Query: db.books.createIndex({ "authors": 1 })
Compound Index:
Introduction to Compound Indexing:
Compound Indexing in MongoDB marks a shift from single-field focus to a more comprehensive approach. This indexing strategy involves creating an index on multiple fields within a document. The goal is to enhance query performance when filtering and sorting are based on multiple criteria. Instead of relying on separate indexes for each field, a Compound Index consolidates the power of several fields, offering a versatile solution for complex queries.
Ordering Fields for Effective Compound Indexing:
The effectiveness of a Compound Index lies not only in the fields included but also in their strategic order. MongoDB leverages the order of fields in the index to optimize queries. It's crucial to prioritize fields with higher selectivity, often those with unique or varied values. For instance, if frequent queries involve filtering by "field1" and then sorting by "field2," the Compound Index should have "field1" as the leading field. This ensures optimal query performance by aligning with the specific ordering and filtering patterns commonly employed in your data retrieval needs.
Syntax: db.collection.createIndex({ "field1": 1, "field2": -1, ... })
Advanced Indexing Techniques
Optimal Compound Index:
Strategies for Optimizing Compound Indexes:
Optimizing Compound Indexes in MongoDB requires thoughtful strategies to maximize efficiency. Instead of a one-size-fits-all approach, consider the specific needs of your queries. Strategies involve identifying key equality fields, sorting fields, and range filters. This intentional approach tailors the compound index to the unique requirements of your data retrieval, significantly enhancing query performance.
Ideal Method for Creating Compound Index:
Creating an optimal Compound Index involves a systematic approach:
Equality Fields: Identify fields frequently used for equality matches in queries.
Sort Fields: Prioritize fields used for sorting to enhance query performance.
Range Filters: Recognize fields involved in range filters for efficient indexing.
The above is known as ESR (Equality, Sort, Range) rule.
Best Practices for Maximum Efficiency:
To achieve maximum efficiency with Compound Indexing, adhere to best practices that align with MongoDB's indexing principles and strategies. Prioritize fields with high selectivity for optimal results. Regularly execute explain() on your queries to evaluate index usage and identify areas for improvement. Modify indexes based on the output of explain() to continually refine and adapt to evolving query patterns.
Wildcard Index:
Definition and Use Cases:
Wildcard Indexing in MongoDB introduces a dynamic and versatile approach to indexing that goes beyond exact matches. Unlike traditional indexes, Wildcard Indexing allows for partial matching based on patterns or wildcards. This means you can efficiently query for documents that match a specific pattern rather than a complete value. For example, a Wildcard Index can be immensely useful when dealing with datasets containing text fields and you need to find entries that contain a particular substring, prefix, or suffix.
Use Cases:
- Ideal for scenarios where you need to search for partial or incomplete values within a field.
- Efficient for text search functionalities where you want to match patterns rather than exact values.
- Useful in situations where the exact values may vary, but a pattern remains constant.
Practical Implementation of Wildcard Indexing:
Implementing Wildcard Indexing involves leveraging MongoDB's text search capabilities and the use of wildcard characters like "*", "?", or others. Let's take a practical example of a collection containing user names, and you want to find users whose names contain the substring "john". By creating a Wildcard Index, you can efficiently execute queries to retrieve matching documents without specifying the complete name.
Syntax: db.collection.createIndex({“$**”:1});
Query: db.user.createIndex({“name.$**”:1});
Partial Index:
Definition and Use Cases:
Partial Indexing in MongoDB introduces a selective approach to indexing, where indexes are created based on a specified condition, rather than covering the entire collection. Unlike full indexes, partial indexes focus on a subset of documents, optimizing performance for specific queries while conserving storage space. This technique is particularly valuable in scenarios where a subset of your data requires specialized indexing to enhance query efficiency.
Use Cases:
- Efficiently index documents that meet specific criteria, reducing index size.
- Ideal for scenarios where certain fields or values are critical for a subset of queries.
- Useful in situations where optimizing specific queries takes precedence over indexing the entire collection.
Practical Implementation of Partial Indexing:
Implementing Partial Indexing involves specifying a filter expression to index only documents that satisfy certain conditions. Let's consider a scenario where you have a collection of "products," and you frequently query for products with a specific "status" value, such as "available." By creating a Partial Index based on the condition where "status" is equal to "available," you can significantly improve query performance for this subset of data.
Syntax: db.collection.createIndex({field:1},{partialFilterExpression: {field:{range}}});
Query: db.products.createIndex({status:1},{partialFilterExpression:{status:”available”}});
Sparse Index:
Use of Sparse Indexing in MongoDB:
Sparse Indexing provides a flexible and efficient approach in MongoDB by creating indexes only for documents that contain a specific field. Unlike traditional indexes that include all documents, sparse indexes are selective, focusing on those that have the indexed field. This indexing strategy is particularly beneficial when dealing with sparse or irregularly populated data, conserving resources and optimizing query performance.
Situations Where Sparse Indexing is Beneficial:
Sparse Indexing proves advantageous in various scenarios where the presence of an indexed field is irregular or optional. This technique shines in situations where:
- The indexed field is not present in all documents.
- There's a need to index documents with specific attributes.
- Resource optimization is crucial, and indexing every document is impractical.
Syntax: db.collection.createIndex({“field”:1},{sparse:true});
Cluster Index:
Explanation of Cluster Indexing:
Cluster Indexing in MongoDB refers to the practice of organizing and storing data on disk based on the structure of the index itself. Unlike traditional indexes that point to the location of data in a separate data file, a Cluster Index directly determines the physical order of data storage on disk. This means that the data in the collection is stored in the same order as the index. Cluster Indexing is often associated with improving query performance by reducing the number of disk I/O operations required to retrieve data.
When to Consider Cluster Indexes in MongoDB:
Consider utilizing Cluster Indexes in MongoDB when specific scenarios demand enhanced query performance and reduced disk I/O. Situations where Cluster Indexes prove beneficial include:
- Frequently queried fields align with the index's order, optimizing retrieval.
- Range queries or sorting operations on a specific field are common in your workload.
- Your data retrieval patterns align with the physical order determined by the index.
Timeseries Indexes:
Overview of Timeseries Indexing:
Timeseries Indexing in MongoDB is a specialized approach designed to optimize the storage and retrieval of time-driven or chronologically ordered data. This indexing strategy focuses on efficiently handling datasets where time is a critical factor, such as sensor readings, logs, or any time-series data. Timeseries Indexes in MongoDB aim to enhance query performance by structuring the index to align with the temporal nature of the data, facilitating fast and efficient retrieval based on time-oriented queries.
Applications in Time-Driven Data Scenarios:
Timeseries Indexes prove invaluable in various scenarios where time-driven data plays a crucial role. Consider implementing Timeseries Indexing when dealing with:
- Sensor data where readings are collected over time.
- Log files recording events in chronological order.
- Financial data with timestamped transactions.
- Any scenario where temporal order significantly influences query patterns.
Syntax:
db.createCollection(“Collection_Name”,{timeseries:{
timefield:”timestamp”,
metafield:”metadata”,
granularity: “hours”}});
Monitoring Index Usage and Performance
Identifying Unused Indexes:
Efficient index usage is crucial for maintaining MongoDB performance. One method to identify unused indexes is by leveraging the $indexStats aggregation pipeline. Execute the query
db.collection.aggregate([{$indexStats:{}}])
to obtain a comprehensive overview of all indexes, including the accesses and ops values. If the accesses value is 0, it indicates that the index is not actively used. Regularly monitoring and eliminating such unused indexes helps conserve storage space and ensures an optimized indexing strategy.
Profiling Slow Queries:
Profiling slow queries is essential for identifying performance bottlenecks. By enabling the profiler with
db.setProfilingLevel(1, { slowms: 30 })
MongoDB captures queries that exceed a specified threshold (30 ms in this case). To retrieve the details of slow queries, execute the query
db.system.profile.find({ op: 'query', ns: 'your_namespace' }).sort({ ts: -1 }).limit(1)
This query fetches the most recent slow query, allowing you to analyze and optimize queries that impact performance.
Conclusion:
In conclusion, MongoDB indexing strategies play a pivotal role in shaping the performance and efficiency of your database and caters to diverse data scenarios.
Key Takeaways on MongoDB Indexing Strategies:
- Choose indexing strategies based on your specific use case and query patterns.
- Single Field Indexing is effective for simple queries on a single field, while Compound Indexing caters to more complex scenarios.
- Specialized indexes like Wildcard and Timeseries Indexes address unique requirements in text search and time-driven data scenarios, respectively.
- Consider Partial and Sparse Indexing to optimize storage and performance for subsets of your data.
Encouragement to Apply Knowledge for Enhanced Database Performance:
- Armed with a deeper understanding of MongoDB indexing, we encourage you to apply this knowledge judiciously to enhance the performance of your MongoDB databases.
- Regularly monitor and assess index usage, identifying opportunities to eliminate unused indexes and streamline storage.
- Leverage profiling tools to identify and optimize slow queries, ensuring a responsive and efficient database.





